
Nvidia에서 TensorRT(TRT)와 Triton Inference Server(TRTIS)에 대해 워크샵을 진행한 내용이 있어서 정리하고자 한다(워크샵 영상 및 자료 링크)(TRT Quickstart Github)
0. Introduction
모델 학습이 끝난 이후, 실제 production 환경에서 모델을 서빙할 때 필요한 부분들은 학습할 때와는 다르다. 가장 간단한 방식은 .predict()/.forward()를 실행하는 것이다. 하지만 더 속도와 TPS를 고민하고 더 좋은 방식이 없을지 생각하다 보면 다음과 같은 질문들이 떠오를 수 있다.
- Is there something more we can do with our model now that we don’t need to train anymore?
- Is there something better we can do than calling a high level .predict()/.forward() function?
TRT, TRTIS는 학습이 완료된 모델을 inference만 할 때 성능 향상을 위해 사용할 수 있는 프레임워크로, Nvidia GPU에 최적화된 솔루션이다. OpenAI도 TRTIS로 서빙을 하고 있고 벤치마크 테스트 시 매우 큰 속도 향상을 경험할 수 있다.
1. TensorRT Workflow
Nvidia 홈페이지에서는 TensorRT를 "NVIDIA® TensorRT™, an SDK for high-performance deep learning inference, includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for inference applications."와 같이 설명하고 있다. 여기서 중요한 내용은 inference optimizer과 runtime이다.
워크샵 자료에서도 다음과 같이 설명하고 있다.
- High-performance framework makes it easy to develop GPU-accelerated inference
- Optimized inference for a given trained neural network and target GPU
- Supports deployment of tf32, fp32,fp16,int8 inference
- Includes both converters and optimized runtimes
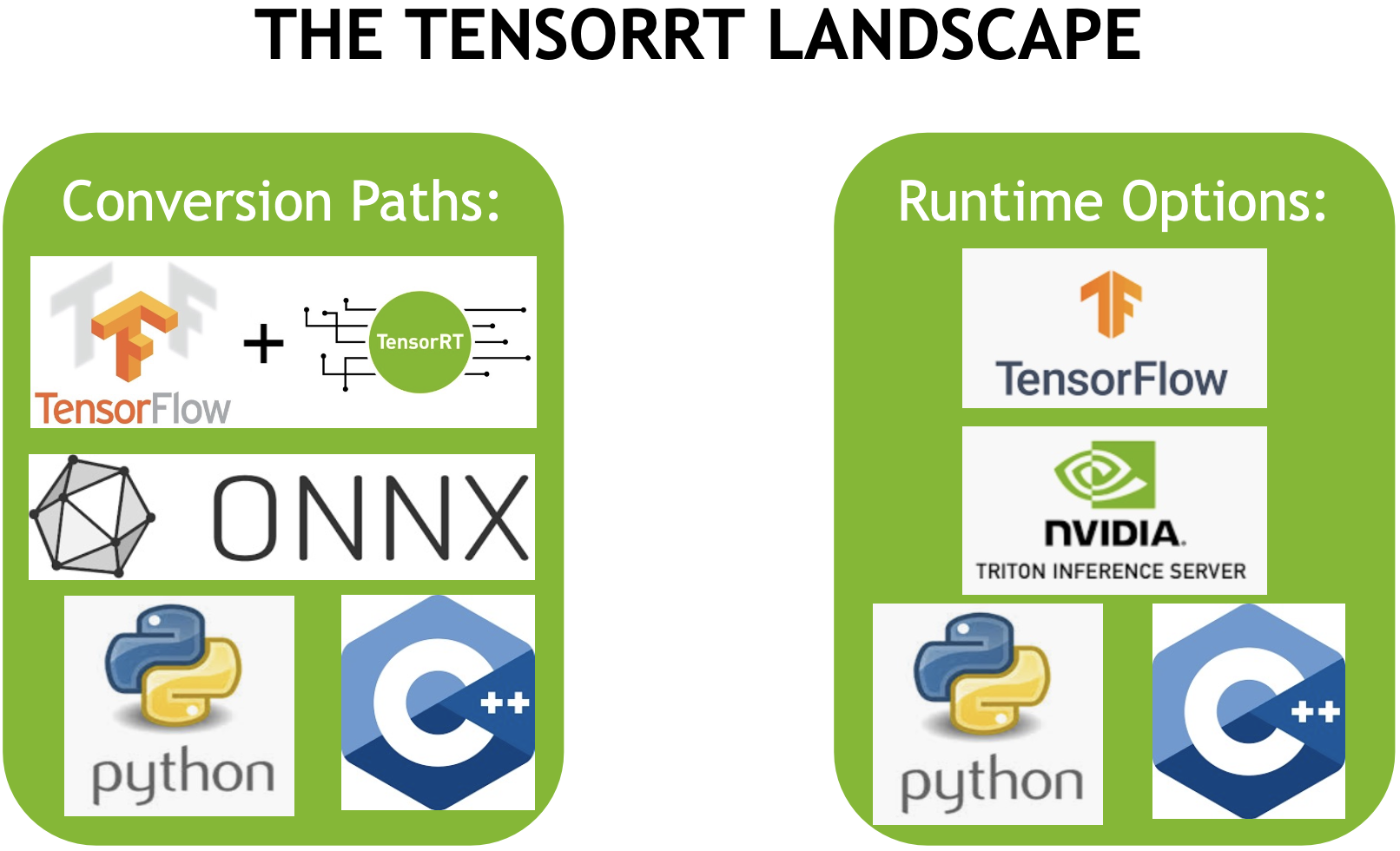
Conversion과 Runtime을 위해 기억해야될 그림은 다음과 같다. Conversion에서 사용할 수 있는 방법 3가지와 Runtime에서 사용할 수 있는 방법 3가지이다.
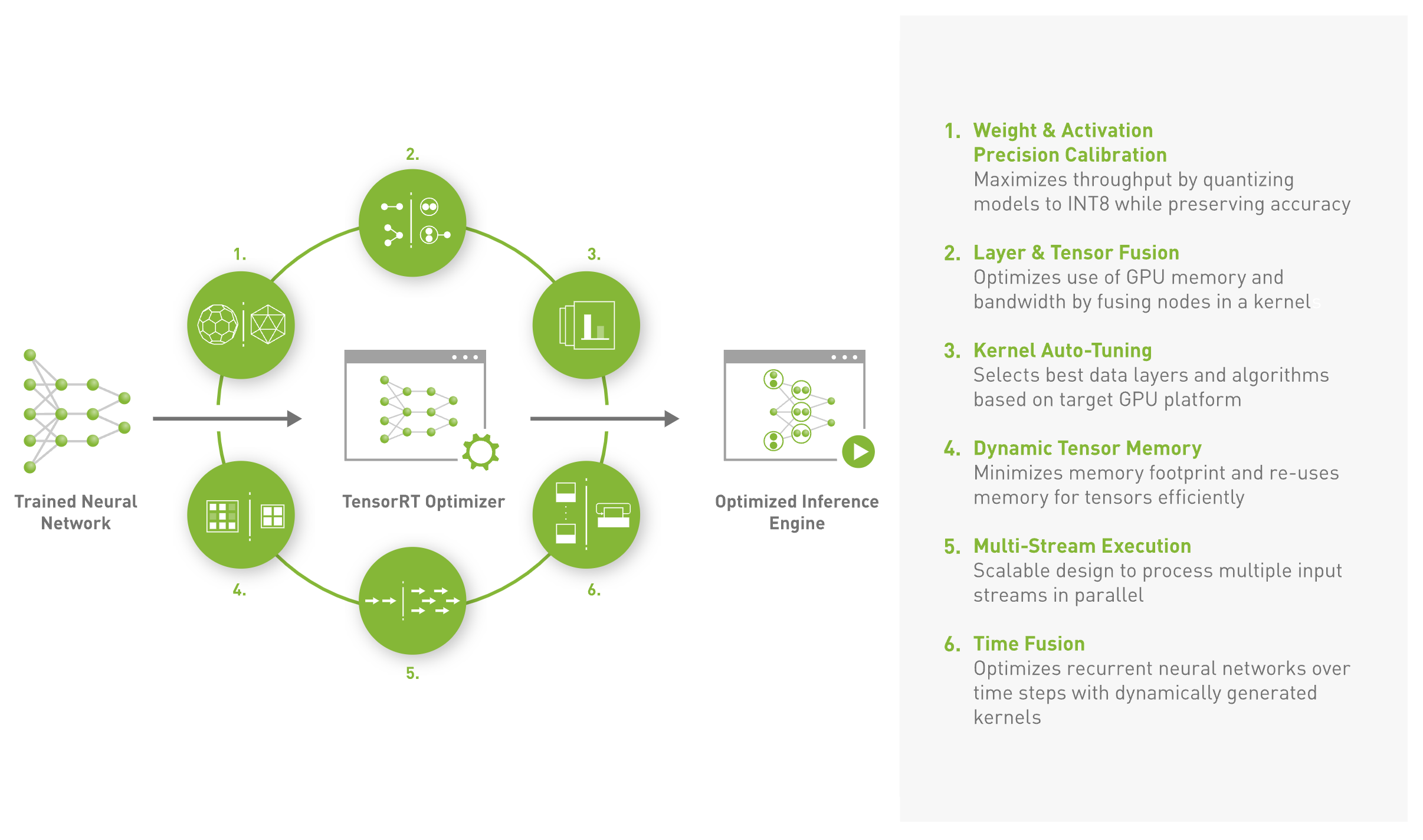
Nvidia에서 설명하는 TRT의 주요 기능은 다음과 같다.
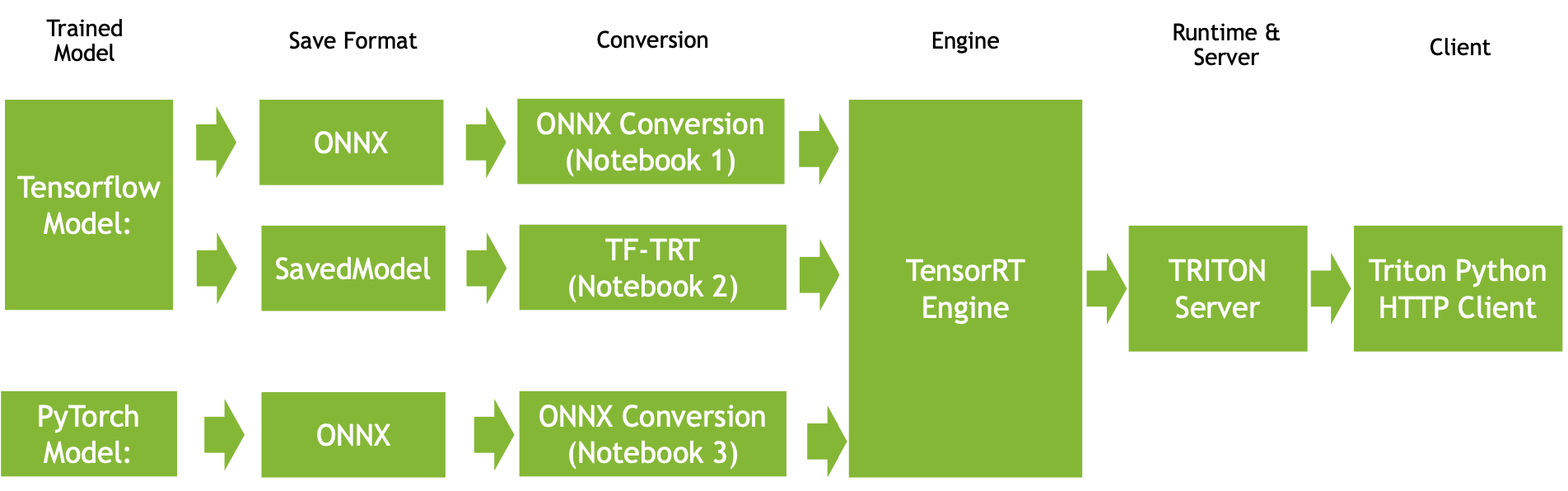
TRT를 통해 Inference Server를 만들기 위해서는 TensorFlow, PyTorch로 학습한 모델을 ONNX, SavedModel로 형식을 변환하고, conversion을 통해 TensorRT Engine으로 만들고, runtime으로 inference sever를 띄우는 과정을 거쳐야 한다. 구체적인 그림은 다음과 같으며, Notebook 1과 같이 표시가 되어있는 것은 본문 상단의 Github 링크를 참고하면 된다.
TensorRT를 사용하면 'trained model'을 'optimize'시키고 'Inference server'를 구축할 수 있으며, 그 중에서 다음과 같은 포인트들을 생각하면서 진행해야 한다.
- How should I export my model to a format TRT understands?
- What batch size am I using?
- What precision am I using?
- How am I converting my model?
- What runtime am I using?
| 1) Save a Model |  |
| 2) Select a Batch Size |  |
| 3) Select a Precision |   |
| 4) Select a Conversion Path |  |
| 5) Select and Deploy to a Runtime |  |
| *Hardware Considerations |  |
2. TensorRT의 Behind the Scenes
1) Graph Optimization
TensorRT가 학습이 완료된 모델을 최적화 하는 내용은 다음과 같다.

기본적으로 연산량을 줄이기 위해서는 작은 연산들을 통합하여 큰 matrix 하나에서 모든 연산이 이루어지는게 좋다. 이를 위해 여러 layer에서 공통적으로 사용되는 layer는 통합시켜 하나의 연산으로 만드는 것이 좋다. 이렇게 해도 되는 이유는 inference시에는 gradient를 계산하지 않아도 되기 때문이다(!)
 |
   |
2) Auto-Tuning
TensorRT는 Graph Optimization을 위해 dummy data를 넣고 layer의 성능을 측정하는 과정을 여러번 거친다. 이를 통해 가장 좋은 graph optimization을 얻을 수 있다.

3. TensorRT Conversion
0) Introduction
학습이 완료된 모델을 TensorRT로 변환하는 방법은 크게 3가지 방법이 있다. 그 중 ONNX로 변환하고 TRT로 가는 방식이 제일 많이 사용되며 특별한 경우가 아니면 이를 사용하는 것이 권장된다.
아래 그림에서는 TensorFlow를 기반으로 설명되어 있지만, PyTorch도 동일하다.
 |
Flexible and Automatic: Can automatically work around/ignore unsupported layers |
 |
Fast and Automatic: but requires plugins for unsupported layers
(제일 사람들이 많이 사용하는 방식임) |
 |
Fast and Flexible: but not automatic – must manually construct a network using TRT ops |
1) ONNX란 무엇인가?
ONNX는 모델 parameter, operation을 framework에 종속되지 않게 시작된 프로젝트이며, 파일 표현 형식(graph)이다.
- ONNX – Open Neural Network eXchange (.onnx) format
- Framework agnostic format that TRT supports directly(community effort standardized across many organizations)
- PyTorch can export to it using torch.onnx
- Tensorflow can export to it using tf2onnx or keras2onnx



4. Runtime Environments
0) Introduction
변환된 TRT 모델을 사용하여 Inference Sever를 구성하는 방식은 크게 3가지가 있다. ONNX로 변환된 모델이 있고 특별한 상황이 아니라면 Nvidia의 Triton을 사용하는 것이 권장된다.
 |
Possible only when using TF-TRT, default option for TF-TRT models (PyTorch의 경우 TorchServe를 사용할 수 있음) |
 |
Serving and Load Balancing: Great for serving models over HTTP ...or doing multi-GPU inference! 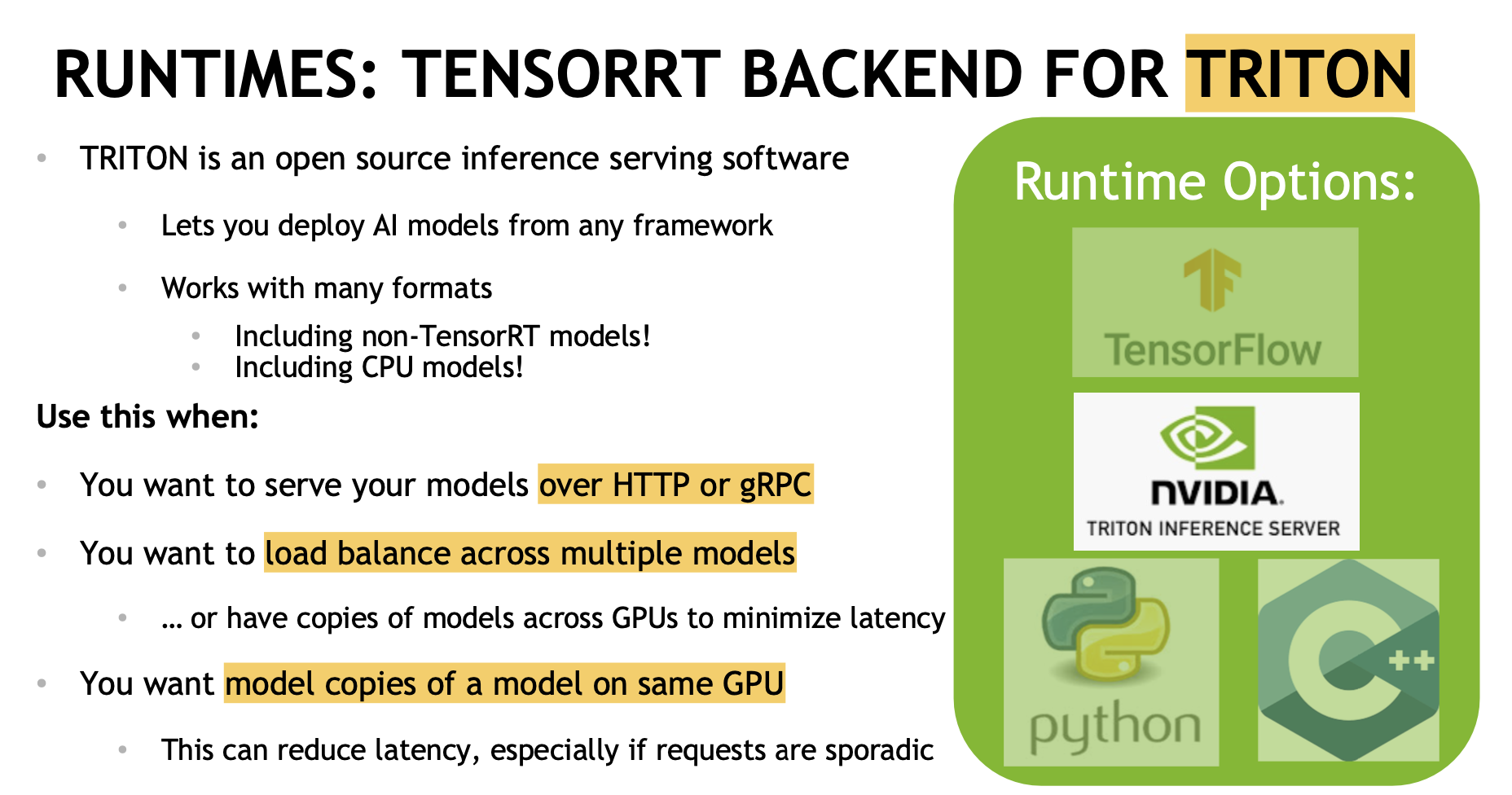 |
 |
Fast, but requires more effort: i.e. memory management, device-host copies, etc
|
이 외로 MS에서 제공하는 ONNX Runtime, TRTorch 등이 있다.
2) Triton Workflow
     |
5. Conclusion

'개발' 카테고리의 다른 글
| [fastapi] logging format 설정 (0) | 2023.07.08 |
|---|---|
| [Miniconda] CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'. 에러 (0) | 2023.07.08 |
| [linux] port를 점유하고 있는 pid 찾기 (0) | 2023.06.02 |
| [linux] pid로 실행중인 파일 찾기 (0) | 2023.06.02 |
| [Docker] Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? 해결 (0) | 2023.05.22 |
Nvidia에서 TensorRT(TRT)와 Triton Inference Server(TRTIS)에 대해 워크샵을 진행한 내용이 있어서 정리하고자 한다(워크샵 영상 및 자료 링크)(TRT Quickstart Github)
0. Introduction
모델 학습이 끝난 이후, 실제 production 환경에서 모델을 서빙할 때 필요한 부분들은 학습할 때와는 다르다. 가장 간단한 방식은 .predict()/.forward()를 실행하는 것이다. 하지만 더 속도와 TPS를 고민하고 더 좋은 방식이 없을지 생각하다 보면 다음과 같은 질문들이 떠오를 수 있다.
- Is there something more we can do with our model now that we don’t need to train anymore?
- Is there something better we can do than calling a high level .predict()/.forward() function?
TRT, TRTIS는 학습이 완료된 모델을 inference만 할 때 성능 향상을 위해 사용할 수 있는 프레임워크로, Nvidia GPU에 최적화된 솔루션이다. OpenAI도 TRTIS로 서빙을 하고 있고 벤치마크 테스트 시 매우 큰 속도 향상을 경험할 수 있다.
1. TensorRT Workflow
Nvidia 홈페이지에서는 TensorRT를 "NVIDIA® TensorRT™, an SDK for high-performance deep learning inference, includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for inference applications."와 같이 설명하고 있다. 여기서 중요한 내용은 inference optimizer과 runtime이다.
워크샵 자료에서도 다음과 같이 설명하고 있다.
- High-performance framework makes it easy to develop GPU-accelerated inference
- Optimized inference for a given trained neural network and target GPU
- Supports deployment of tf32, fp32,fp16,int8 inference
- Includes both converters and optimized runtimes
Conversion과 Runtime을 위해 기억해야될 그림은 다음과 같다. Conversion에서 사용할 수 있는 방법 3가지와 Runtime에서 사용할 수 있는 방법 3가지이다.
Nvidia에서 설명하는 TRT의 주요 기능은 다음과 같다.
TRT를 통해 Inference Server를 만들기 위해서는 TensorFlow, PyTorch로 학습한 모델을 ONNX, SavedModel로 형식을 변환하고, conversion을 통해 TensorRT Engine으로 만들고, runtime으로 inference sever를 띄우는 과정을 거쳐야 한다. 구체적인 그림은 다음과 같으며, Notebook 1과 같이 표시가 되어있는 것은 본문 상단의 Github 링크를 참고하면 된다.
TensorRT를 사용하면 'trained model'을 'optimize'시키고 'Inference server'를 구축할 수 있으며, 그 중에서 다음과 같은 포인트들을 생각하면서 진행해야 한다.
- How should I export my model to a format TRT understands?
- What batch size am I using?
- What precision am I using?
- How am I converting my model?
- What runtime am I using?
| 1) Save a Model | |
| 2) Select a Batch Size | |
| 3) Select a Precision | |
| 4) Select a Conversion Path | |
| 5) Select and Deploy to a Runtime | |
| *Hardware Considerations | |
2. TensorRT의 Behind the Scenes
1) Graph Optimization
TensorRT가 학습이 완료된 모델을 최적화 하는 내용은 다음과 같다.
기본적으로 연산량을 줄이기 위해서는 작은 연산들을 통합하여 큰 matrix 하나에서 모든 연산이 이루어지는게 좋다. 이를 위해 여러 layer에서 공통적으로 사용되는 layer는 통합시켜 하나의 연산으로 만드는 것이 좋다. 이렇게 해도 되는 이유는 inference시에는 gradient를 계산하지 않아도 되기 때문이다(!)
|
|
2) Auto-Tuning
TensorRT는 Graph Optimization을 위해 dummy data를 넣고 layer의 성능을 측정하는 과정을 여러번 거친다. 이를 통해 가장 좋은 graph optimization을 얻을 수 있다.
3. TensorRT Conversion
0) Introduction
학습이 완료된 모델을 TensorRT로 변환하는 방법은 크게 3가지 방법이 있다. 그 중 ONNX로 변환하고 TRT로 가는 방식이 제일 많이 사용되며 특별한 경우가 아니면 이를 사용하는 것이 권장된다.
아래 그림에서는 TensorFlow를 기반으로 설명되어 있지만, PyTorch도 동일하다.
|
Flexible and Automatic: Can automatically work around/ignore unsupported layers |
|
Fast and Automatic: but requires plugins for unsupported layers
(제일 사람들이 많이 사용하는 방식임) |
|
Fast and Flexible: but not automatic – must manually construct a network using TRT ops |
1) ONNX란 무엇인가?
ONNX는 모델 parameter, operation을 framework에 종속되지 않게 시작된 프로젝트이며, 파일 표현 형식(graph)이다.
- ONNX – Open Neural Network eXchange (.onnx) format
- Framework agnostic format that TRT supports directly(community effort standardized across many organizations)
- PyTorch can export to it using torch.onnx
- Tensorflow can export to it using tf2onnx or keras2onnx
4. Runtime Environments
0) Introduction
변환된 TRT 모델을 사용하여 Inference Sever를 구성하는 방식은 크게 3가지가 있다. ONNX로 변환된 모델이 있고 특별한 상황이 아니라면 Nvidia의 Triton을 사용하는 것이 권장된다.
|
Possible only when using TF-TRT, default option for TF-TRT models (PyTorch의 경우 TorchServe를 사용할 수 있음) |
|
Serving and Load Balancing: Great for serving models over HTTP ...or doing multi-GPU inference! |
|
Fast, but requires more effort: i.e. memory management, device-host copies, etc
|
이 외로 MS에서 제공하는 ONNX Runtime, TRTorch 등이 있다.
2) Triton Workflow
|
5. Conclusion
'개발' 카테고리의 다른 글
| [fastapi] logging format 설정 (0) | 2023.07.08 |
|---|---|
| [Miniconda] CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'. 에러 (0) | 2023.07.08 |
| [linux] port를 점유하고 있는 pid 찾기 (0) | 2023.06.02 |
| [linux] pid로 실행중인 파일 찾기 (0) | 2023.06.02 |
| [Docker] Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? 해결 (0) | 2023.05.22 |