
RNN 계열의 sequence model에 attention을 적용하여 비약적인 성능향상을 확인한 이후, attention만을 사용하면 과연 어떤 성능을 보여줄지에 대한 연구가 Attention is All you need 논문이다.
1. Introduction
RNN, LSTM, GRU 등의 sequence modelling approach들은 long sequence에 취약하다는 한계점이 있다. 하지만 attention mechanism이 적용되면서 sequence에서의 위치와 관계없이 dependency를 반영할 수 있게 되었다.
Transformer 모델은 recurrence라는 특성(과거의 output의 현재의 input으로 사용되는 점)을 없애고 attention mechanism만을 적용하여 global dependency를 모델링하였으며, 결과 parallelization을 적극적으로 활용하였다.

2. Model Architecture
Transormer는 Encoder + Decoder로 구성되어 있다.
- Encoder: 입력 sequence의 임베딩(symbol representation)을 연속 공간에서의 임베딩(continuouse representation $Z$)로 변환
- Decoder: symbol에 대한 출력물을 하나씩 생성
1) Encoder and Decoder stacks
각 Encoder, Decoder는 모두 multi-head attention, feed-forward network의 sub layer로 구성된 attention block이 $N$개씩 stack되어 있는 구조이다. 각 sub layer는 risidual connection + layer normalization으로 연결되어 있다. 때문에 embedding layer, 모든 sub layer들의 차원은 $d_{model}=512$으로 통일하였다.
Decoder의 경우 Encoder의 출력물과의 attention을 계산하기 위한 multi-head attention layer가 추가적으로 존재한다.
2) Attention
Attetion에는 여러 종류가 있는데 Transformer 모델에서는 가장 기본적인 attention mechanism을 사용하였다. Attention function은 query와 set of key-value pair와의 mapping으로 이해할 수 있다. query, key의 function output을 weight으로 사용하여 value들에 대해 weighted sum을 계산하게 된다.

i. Scaled Dot-Production Attention
Transformer 모델의 가장 핵심이 되는 부분이며 다음과 같은 과정으로 계산된다.
- query와 모든 key에 대한 dot product $\rightarrow \sqrt{d_{k}}$으로 scaling $\rightarrow$ softmax weight 계산
- query, key: $d_{k}$차원 / value: $d_{v}$ 차원
$$Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$$
scaling을 하는 이유는 $d_{k}$ 값이 커지면 softmax 취했을 때 gradient가 굉장히 작아지기 때문이다.
ii. Multi-Head attention
attention을 한번 취하는 것 보다 여러번 취하는게 더 효과적이다. 각각의 attention function이 여러 attention을 계산하도록 학습하기 때문이다(attention function별로 값이 어떻게 다른지에 대한 결과들도 있다). 이를 위해 query, key, value를 $h$번 만큼 다르게 linearly project하여 parallel attention을 계산한다.
$$Multihead(Q,K,V) = Concat(head_{1}, ..., head_{h})W^{Q}$$
$$head_{i} = Attention(QW_{i}^{Q}, KW_{i}^{K}, VW_{i}^{V})$$
- $h=8, d_{k}=d_{v}=d_{model}/h=64$
- token embedding을 linearly project하기 위해 $W^{Q}, W^{K}, W^{V}$ 곱하여 $Q, K, V$ 생성 $\rightarrow W_{i}^{Q} \in \mathbb{R}^{d_{model} \times d_{k}}, W_{i}^{K} \in \mathbb{R}^{d_{model} \times d_{k}}, W_{i}^{V} \in \mathbb{R}^{d_{model} \times d_{v}}, W^{O} \in \mathbb{R}^{hd_{v} \times d_{model}}$
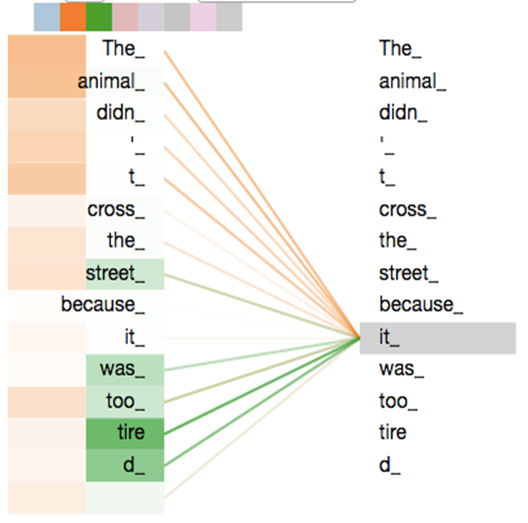
iii. Application of Attention in Transformer
Transformer에서는 multi-head attention이 3가지 형태로 쓰인다.
- encoder self-attention: query, key, value는 같은 위치의 이전 layer의 output
- encoder-decoder attention layer: query는 decoder sub layer의 output이며, key와 value를 encoder output을 활용함. 즉, 각 decoding step에서 모든 input sequence와의 attention을 계산함
- decoder self-attention: full attention계산 이후 현재 time-stamp 이후의 값은 아주 작은 값(-1e10)으로 masking한 후 softmax 계산(illegal connection)
3) Position-wise Feed-Forward Networks
각 position별 embedding에 feed-forward network을 적용한다.
- $FFN(x) = max(0, xW_{1}+b_{1})W_{2}+b_{2}$
- input, output: $d_{model}=512$ / inner-layer $d_{ff}=2048$
4) Embeddings and Softmax
embedding matrix를 학습하며, input&output 동일하게 사용한다.
5) Positional Encodding
Attention mechanism에서는 recurrence나 convolution이 없기 때문에 어떤 token에 대한 위치 정보가 전혀 없다. 때문에 별도로 relative 또는 absolute position 정보를 줘야 한다. Transformer에서는 absolute positional encoding을 사용했지만 후속 연구들에서는 relative positional encoding을 자주 사용하는 것을 볼 수 있다.
$$PE_{(pos, 2i)} = sin(pos/10000^{2i/d_{model}})$$
$$PE_{(pos, 2i+1)} = cos(pos/10000^{2i/d_{model}})$$
- position: token의 위치
- $i$: embedding dimension
'논문 및 개념 정리' 카테고리의 다른 글
| [2018] Universal Language Model Fine-tuning for Text Classification(ULMfiT) (0) | 2021.03.15 |
|---|---|
| [2018] Deep contextualized word representations(ELMo) (0) | 2021.03.15 |
| Big Bird Implementation details (0) | 2021.02.16 |
| [2019] Big Bird: Transformers for Longer Sequences (0) | 2021.02.15 |
| Exploring Transfer Learning with T5 : the Text-To-Text Transfer Transformer (2) (0) | 2020.06.04 |
RNN 계열의 sequence model에 attention을 적용하여 비약적인 성능향상을 확인한 이후, attention만을 사용하면 과연 어떤 성능을 보여줄지에 대한 연구가 Attention is All you need 논문이다.
1. Introduction
RNN, LSTM, GRU 등의 sequence modelling approach들은 long sequence에 취약하다는 한계점이 있다. 하지만 attention mechanism이 적용되면서 sequence에서의 위치와 관계없이 dependency를 반영할 수 있게 되었다.
Transformer 모델은 recurrence라는 특성(과거의 output의 현재의 input으로 사용되는 점)을 없애고 attention mechanism만을 적용하여 global dependency를 모델링하였으며, 결과 parallelization을 적극적으로 활용하였다.
2. Model Architecture
Transormer는 Encoder + Decoder로 구성되어 있다.
- Encoder: 입력 sequence의 임베딩(symbol representation)을 연속 공간에서의 임베딩(continuouse representation
- Decoder: symbol에 대한 출력물을 하나씩 생성
1) Encoder and Decoder stacks
각 Encoder, Decoder는 모두 multi-head attention, feed-forward network의 sub layer로 구성된 attention block이
Decoder의 경우 Encoder의 출력물과의 attention을 계산하기 위한 multi-head attention layer가 추가적으로 존재한다.
2) Attention
Attetion에는 여러 종류가 있는데 Transformer 모델에서는 가장 기본적인 attention mechanism을 사용하였다. Attention function은 query와 set of key-value pair와의 mapping으로 이해할 수 있다. query, key의 function output을 weight으로 사용하여 value들에 대해 weighted sum을 계산하게 된다.
i. Scaled Dot-Production Attention
Transformer 모델의 가장 핵심이 되는 부분이며 다음과 같은 과정으로 계산된다.
- query와 모든 key에 대한 dot product
- query, key:
scaling을 하는 이유는
ii. Multi-Head attention
attention을 한번 취하는 것 보다 여러번 취하는게 더 효과적이다. 각각의 attention function이 여러 attention을 계산하도록 학습하기 때문이다(attention function별로 값이 어떻게 다른지에 대한 결과들도 있다). 이를 위해 query, key, value를
-
- token embedding을 linearly project하기 위해
iii. Application of Attention in Transformer
Transformer에서는 multi-head attention이 3가지 형태로 쓰인다.
- encoder self-attention: query, key, value는 같은 위치의 이전 layer의 output
- encoder-decoder attention layer: query는 decoder sub layer의 output이며, key와 value를 encoder output을 활용함. 즉, 각 decoding step에서 모든 input sequence와의 attention을 계산함
- decoder self-attention: full attention계산 이후 현재 time-stamp 이후의 값은 아주 작은 값(-1e10)으로 masking한 후 softmax 계산(illegal connection)
3) Position-wise Feed-Forward Networks
각 position별 embedding에 feed-forward network을 적용한다.
-
- input, output:
4) Embeddings and Softmax
embedding matrix를 학습하며, input&output 동일하게 사용한다.
5) Positional Encodding
Attention mechanism에서는 recurrence나 convolution이 없기 때문에 어떤 token에 대한 위치 정보가 전혀 없다. 때문에 별도로 relative 또는 absolute position 정보를 줘야 한다. Transformer에서는 absolute positional encoding을 사용했지만 후속 연구들에서는 relative positional encoding을 자주 사용하는 것을 볼 수 있다.
- position: token의 위치
-
'논문 및 개념 정리' 카테고리의 다른 글
| [2018] Universal Language Model Fine-tuning for Text Classification(ULMfiT) (0) | 2021.03.15 |
|---|---|
| [2018] Deep contextualized word representations(ELMo) (0) | 2021.03.15 |
| Big Bird Implementation details (0) | 2021.02.16 |
| [2019] Big Bird: Transformers for Longer Sequences (0) | 2021.02.15 |
| Exploring Transfer Learning with T5 : the Text-To-Text Transfer Transformer (2) (0) | 2020.06.04 |