
핵심포인트
- scored-based 평가 방법론이 아닌 ranking-based 평가 방법론 제시
- bot-bot conversation을 활용
0. Abstract
대화시스템(챗봇)의 기술은 계속 발전해나가고 있으나, 효율적이고 안정적인 평가 방법이 부재하다. Accuracy 기반의 측도들이 존재하나, 이러한 값들은 인간의 평가와 연관도가 낮다고 알려져 있다. 또한 기존의 평가 방법론은 인간-챗봇 대화를 통해 챗봇을 평가했었으며, 이는 비용이 클 뿐만 아니라 매우 비효율적이다.
본 연구에서는 Spot The Bot이라는 평가 방법론을 제시한다. Spot The Bot은 기존의 인간-챗봇 대화평가에서 챗봇-챗봇 대화 내역을 사용한다. 평가자는 대화 내역을 보고 해당 발화자가 챗봇인지 아닌지만을 평가하며, 최종적으로 챗봇들의 ranking을 매기게 된다. 모든 대화 시스템은 인간과 비슷한 대화를 가능하게 하는게 목표이므로 매우 적합한 평가방식이며, 발화자가 챗봇임을 들키는 순간을 점수화하여Survival Analysis를 한다면 모델 평가 점수에 대한 의미적인 결과 비교도 가능해진다.
1. Introduction
1.1 챗봇 평가 방식 종류
Human evaluation approach들은 다음과 같이 분류할 수 있다.
- single-turn evaluation vs. multi-turn evaluation
- direct user evaluation vs. expert judge evaluation
Spot The Bot은 챗봇-챗봇 간 multi-turn evaluation 방식이며, 완료된 대화에 대해 평가하므로 expert judge evaluation에 가깝다(꼭 전문가가 평가할 필요는 없다).
1.2 Spot The Bot 프레임워크
Spot The Bot은 다수의 챗봇을 평가하는 효율적인 방법으로, 얼마나 사람처럼 대화할 수 있는지를 평가한다. Spot The Bot은 다음과 같이 두 가지 관찰로부터 고안되었다.
- 챗봇은 사람 간의 대화를 사용하여 학습된다. 떄문에 사람의 대화 방식을 모사할 수 있는지를 평가할 수 있어야 한다.
- 대화가 길어질 수록 챗봇은 사람이 절대 하지 않을 대화 패턴을 보여준다.
2. Spot The Bot
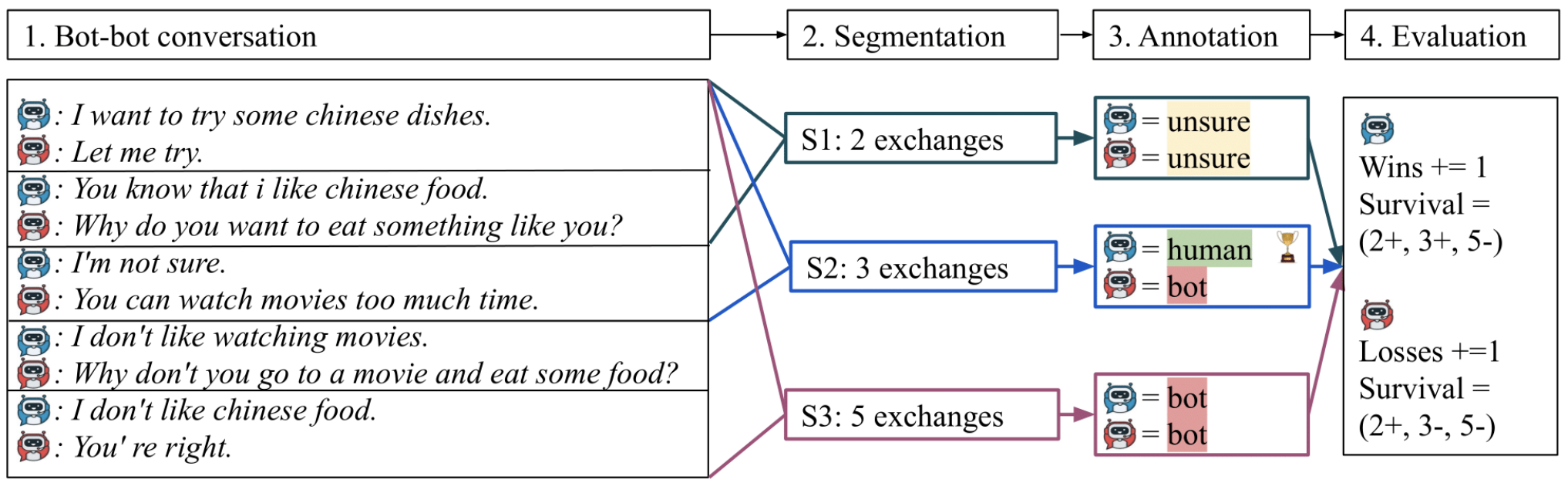
2.1 개요
Spot The Bot은 챗봇 간의 1:1 평가를 토너먼트 형태로 진행하며 평가 방식은 다음과 같다.(*♣: 주목해서 봐야할 좋은 아이디어)
- 선택된 두 챗봇이 1:1로 대화를 이어나간다.
- 대화가 완료된 이후 평가자들에게 해당 챗봇들의 대화 + 사람 간의 대화가 섞인 대화 내역이 보여진다.(♣)
- 평가자는 여러 길이(segmentation)의 대화 내역으로 보고 각 발화자에 대해 human, bot, unsure 중 하나로 평가한다.(♣)
- human 표를 제일 많이 얻은 chatbot이 해당 토너먼트에서 승리한다
Spot The Bot 프레임워크를 통해 챗봇들은 다음 두 가지에 대해 평가된다.
- Ranking: 전체 챗봇 pool에서의 순위
- Survival Analysis: '대화 길이'에 따른 여러 feature의 평가 값(♣)
공식에서 사용될 수식들은 다음과 같다.
- pool of $b$ bots: $\{B_{1}, \dots, B_{b}\}$
- $S_{ij}$: bot $B_{i}, B_{j}$ 간의 대화 내역 중 샘플링 된 대화 내역 set
- 각 대화: $N$개의 sequence of exchange으로 정의($\{e_{0}, \dots, e_{N}\}$)
- 각 exchange: 2개의 turn으로 정의($e_{i} = \{ {t_{0}^{e_{i}}, t_{1}^{e_{i}}} \}$)
*Segmentation
챗봇은 대화 길이가 길어지면 대화 내용이 매우 어색해지므로 챗봇임을 들키기 쉬워진다. 때문에 대화 길이에 따른 챗봇 품질 평가가 이루어져야 한다.
평가자에게 보여지는 Segment는 0부터 $k$턴까지의 대화로 정의된다.() 평가자들의 bias를 줄이기 위해 같은 대화에서의 segments들은 모두 다른 평가자들에게 보여진다. 또한 어느 길이가 평가에 적합한지 알기 어렵기 때문에 여러 개의 $k$값을 사용하였다($k=2,3,5$ 사용).
*Human Conversation Mixing
Human Conversation은 챗봇 학습에 사용된 training set에서 샘플링하여 챗봇-챗봇 대화 내역에 섞는다. 섞는 이유는 평가 점수의 upper bound를 잡기 위한 것도 있지만 평가자가 챗봇 대화 내역만 본다면 모든 발화자를 챗봇으로 평가하는 불상사도 일어날 수 있기 때문이다.
*Annotation
평가자들의 평가 프로세스는 다음과 같이 두 단계로 진행된다.
- 대화 내역에서 각 발화자에 대해 [human, bot, unsure] 중 하나로 태깅
- 결과 해석을 위해 fluency, appropriateness 등의 feature들에 대해 값도 매김
두 번째의 feature들은 챗봇의 survival time에 대한 영향도를 평가하고 평가 결과를 설명하는데 사용된다.
*Features
본 연구에서 사용한 feature는 다음 3가지이다.
- sensibleness: which entities' language is more fluent and grammatically correct?
- specificity: which entities' responses are more sensible?
- fluency: which entities' responses are more specific and explicit in the given context?
첫 두 feature는 대화 속에서 합리적인 대답을 하는 것과 주어진 context에 특정된 알맞은 대화를 하는지를 평가한다. 세 번째 feature는 대화가 문법적으로 알맞고 자연스러운 발화인지를 평가한다.
2.2 Ranking
Spot The Bot Framework는 앞서 설명한 것 처럼 ranking based 평가 시스템이다. 이를 위해 모든 대화들에 대한 labeling이 끝난 이후 ranking에 사용할 Win Function을 정의하여 사용한다.
*Win Function
segmentation set인 $S_{ij}^{k} = {e_{0}, \cdots, e_{k} }$의 각 segment의 두 bot에 대해 [bot, human, unsure] 중 하나로 평가가 이루어진 상황에서 human > unsure > bot 순위로 평가한다. 예를 들어, 어떤 segment $e_{i}$에서 bot $B_{i}$가 human으로, bot $B_{j}$가 unsure로 레이블링 되었다면 A가 이기는 방식이다.
모든 segment들에 대해서 $B_{i}$가 $B_{j}$를 이긴 횟수를 $WINS(B_{i}, B_{j})$이라 한다면 아래와 같은 수식으로 Win Function을 정의할수 있다.
$$\frac{WINS(B_{i}, B_{j})}{WINS(B_{i}, B_{j}) + WINS(B_{j}, B_{i})}$$
*Ranking
Ranking을 계산하기 위해 Microsoft팀에서 고안한 TrueSkill이라는 기법을 활용했다. 이에 대한 정리는 다른 글에서 하고자 한다.
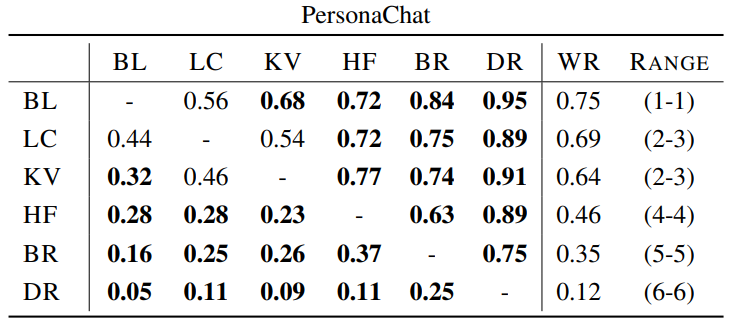
2.3 Survival Analysis
Win Function을 활용한 ranking은 bot들 간의 상대적인 평가이며, 어떤 bot이 얼마나 사람과 비슷한지에 대한 절대적인 평가가 필요하다. Survival Analysis는 bot들이 대화 턴 수가 길어지면 성능 저하 등으로 인해 bot으로 들키는 경향이 커지는 점을 활용한 것으로, 얼마나 많은 턴 수 동안 human으로 느껴지는지를 평가한다.
Survival Analysis의 경우 확률값으로 표현된다. 예를 들어 $k$턴까지의 대화에서 bot인게 들키지 않았다면 살아남았으므로 1이다. 하지만 bot인게 들켰다면 $k$개의 턴 중 어느 시점에서 bot으로 들켰는지 모른다(segment들에 대한 평가가 완료된 시점임). 때문에 segment들에 대한 평가 결과의 평균으로 계산하게 된다.
'논문 및 개념 정리' 카테고리의 다른 글
| [LM] Perplexity 개념 (0) | 2022.02.17 |
|---|---|
| [GPT3] 주요 내용 정리 (0) | 2022.02.16 |
| [2017] On Calibration of Modern Neural Networks (0) | 2021.05.26 |
| [2018] Universal Language Model Fine-tuning for Text Classification(ULMfiT) (0) | 2021.03.15 |
| [2018] Deep contextualized word representations(ELMo) (0) | 2021.03.15 |
핵심포인트
- scored-based 평가 방법론이 아닌 ranking-based 평가 방법론 제시
- bot-bot conversation을 활용
0. Abstract
대화시스템(챗봇)의 기술은 계속 발전해나가고 있으나, 효율적이고 안정적인 평가 방법이 부재하다. Accuracy 기반의 측도들이 존재하나, 이러한 값들은 인간의 평가와 연관도가 낮다고 알려져 있다. 또한 기존의 평가 방법론은 인간-챗봇 대화를 통해 챗봇을 평가했었으며, 이는 비용이 클 뿐만 아니라 매우 비효율적이다.
본 연구에서는 Spot The Bot이라는 평가 방법론을 제시한다. Spot The Bot은 기존의 인간-챗봇 대화평가에서 챗봇-챗봇 대화 내역을 사용한다. 평가자는 대화 내역을 보고 해당 발화자가 챗봇인지 아닌지만을 평가하며, 최종적으로 챗봇들의 ranking을 매기게 된다. 모든 대화 시스템은 인간과 비슷한 대화를 가능하게 하는게 목표이므로 매우 적합한 평가방식이며, 발화자가 챗봇임을 들키는 순간을 점수화하여Survival Analysis를 한다면 모델 평가 점수에 대한 의미적인 결과 비교도 가능해진다.
1. Introduction
1.1 챗봇 평가 방식 종류
Human evaluation approach들은 다음과 같이 분류할 수 있다.
- single-turn evaluation vs. multi-turn evaluation
- direct user evaluation vs. expert judge evaluation
Spot The Bot은 챗봇-챗봇 간 multi-turn evaluation 방식이며, 완료된 대화에 대해 평가하므로 expert judge evaluation에 가깝다(꼭 전문가가 평가할 필요는 없다).
1.2 Spot The Bot 프레임워크
Spot The Bot은 다수의 챗봇을 평가하는 효율적인 방법으로, 얼마나 사람처럼 대화할 수 있는지를 평가한다. Spot The Bot은 다음과 같이 두 가지 관찰로부터 고안되었다.
- 챗봇은 사람 간의 대화를 사용하여 학습된다. 떄문에 사람의 대화 방식을 모사할 수 있는지를 평가할 수 있어야 한다.
- 대화가 길어질 수록 챗봇은 사람이 절대 하지 않을 대화 패턴을 보여준다.
2. Spot The Bot
2.1 개요
Spot The Bot은 챗봇 간의 1:1 평가를 토너먼트 형태로 진행하며 평가 방식은 다음과 같다.(*♣: 주목해서 봐야할 좋은 아이디어)
- 선택된 두 챗봇이 1:1로 대화를 이어나간다.
- 대화가 완료된 이후 평가자들에게 해당 챗봇들의 대화 + 사람 간의 대화가 섞인 대화 내역이 보여진다.(♣)
- 평가자는 여러 길이(segmentation)의 대화 내역으로 보고 각 발화자에 대해 human, bot, unsure 중 하나로 평가한다.(♣)
- human 표를 제일 많이 얻은 chatbot이 해당 토너먼트에서 승리한다
Spot The Bot 프레임워크를 통해 챗봇들은 다음 두 가지에 대해 평가된다.
- Ranking: 전체 챗봇 pool에서의 순위
- Survival Analysis: '대화 길이'에 따른 여러 feature의 평가 값(♣)
공식에서 사용될 수식들은 다음과 같다.
- pool of
- 각 대화:
- 각 exchange: 2개의 turn으로 정의(
*Segmentation
챗봇은 대화 길이가 길어지면 대화 내용이 매우 어색해지므로 챗봇임을 들키기 쉬워진다. 때문에 대화 길이에 따른 챗봇 품질 평가가 이루어져야 한다.
평가자에게 보여지는 Segment는 0부터
*Human Conversation Mixing
Human Conversation은 챗봇 학습에 사용된 training set에서 샘플링하여 챗봇-챗봇 대화 내역에 섞는다. 섞는 이유는 평가 점수의 upper bound를 잡기 위한 것도 있지만 평가자가 챗봇 대화 내역만 본다면 모든 발화자를 챗봇으로 평가하는 불상사도 일어날 수 있기 때문이다.
*Annotation
평가자들의 평가 프로세스는 다음과 같이 두 단계로 진행된다.
- 대화 내역에서 각 발화자에 대해 [human, bot, unsure] 중 하나로 태깅
- 결과 해석을 위해 fluency, appropriateness 등의 feature들에 대해 값도 매김
두 번째의 feature들은 챗봇의 survival time에 대한 영향도를 평가하고 평가 결과를 설명하는데 사용된다.
*Features
본 연구에서 사용한 feature는 다음 3가지이다.
- sensibleness: which entities' language is more fluent and grammatically correct?
- specificity: which entities' responses are more sensible?
- fluency: which entities' responses are more specific and explicit in the given context?
첫 두 feature는 대화 속에서 합리적인 대답을 하는 것과 주어진 context에 특정된 알맞은 대화를 하는지를 평가한다. 세 번째 feature는 대화가 문법적으로 알맞고 자연스러운 발화인지를 평가한다.
2.2 Ranking
Spot The Bot Framework는 앞서 설명한 것 처럼 ranking based 평가 시스템이다. 이를 위해 모든 대화들에 대한 labeling이 끝난 이후 ranking에 사용할 Win Function을 정의하여 사용한다.
*Win Function
segmentation set인
모든 segment들에 대해서
*Ranking
Ranking을 계산하기 위해 Microsoft팀에서 고안한 TrueSkill이라는 기법을 활용했다. 이에 대한 정리는 다른 글에서 하고자 한다.
2.3 Survival Analysis
Win Function을 활용한 ranking은 bot들 간의 상대적인 평가이며, 어떤 bot이 얼마나 사람과 비슷한지에 대한 절대적인 평가가 필요하다. Survival Analysis는 bot들이 대화 턴 수가 길어지면 성능 저하 등으로 인해 bot으로 들키는 경향이 커지는 점을 활용한 것으로, 얼마나 많은 턴 수 동안 human으로 느껴지는지를 평가한다.
Survival Analysis의 경우 확률값으로 표현된다. 예를 들어
'논문 및 개념 정리' 카테고리의 다른 글
| [LM] Perplexity 개념 (0) | 2022.02.17 |
|---|---|
| [GPT3] 주요 내용 정리 (0) | 2022.02.16 |
| [2017] On Calibration of Modern Neural Networks (0) | 2021.05.26 |
| [2018] Universal Language Model Fine-tuning for Text Classification(ULMfiT) (0) | 2021.03.15 |
| [2018] Deep contextualized word representations(ELMo) (0) | 2021.03.15 |