
GPT 모델은 auto-regressive 모델 계열 중 하나이며 특히 GPT3는 transformer 계열 언어모델의 크기에 따른 성능을 매우 잘 보여주었다. 본 글에서는 GPT3 논문의 주요 내용 및 궁금했던 점들을 정리하고자 한다.
궁금한 점들
- in-context learning이란? & few(one, zero)-shot learning이란?
- prompt 및 GPT3 입력
더 좋은 contextualized embedding을 얻기 위한 많은 노력들 끝에 transformer 계열 모델들이 등장했다. 이후 사전학습(pre-training)된 언어모델을 사용하기 위해서 fine-tuning을 거치면 task 데이터셋에 대해서 높은 성능을 보이는 것이 확인되었으나 이는 다음과 같은 한계점들이 있다.
- task별로 fine-tuning을 위한 수만~수십만개의 데이터를 모으는 것은 비현실적임
- pre-training에서 학습한 분포와 task에서 학습한 분포와의 차이로 인해 generalization 능력이 약화되며, task 성능이 좋더라도 해당 task에만 해당되는 over-fitting된 결과일 수 있다.
- 인간은 task가 달라져도 비슷한 수준의 이해능력을 보여준다. task간 전환이 유동적이며 안정적인 성능을 보여주는 모델은 이점이 많다.
GPT3 논문은 이러한 한계점들이 극복가능한지 확인하기 위해 모델 크기에 따른 few(one, zero)-shot learning의 성능을 측정하였다.
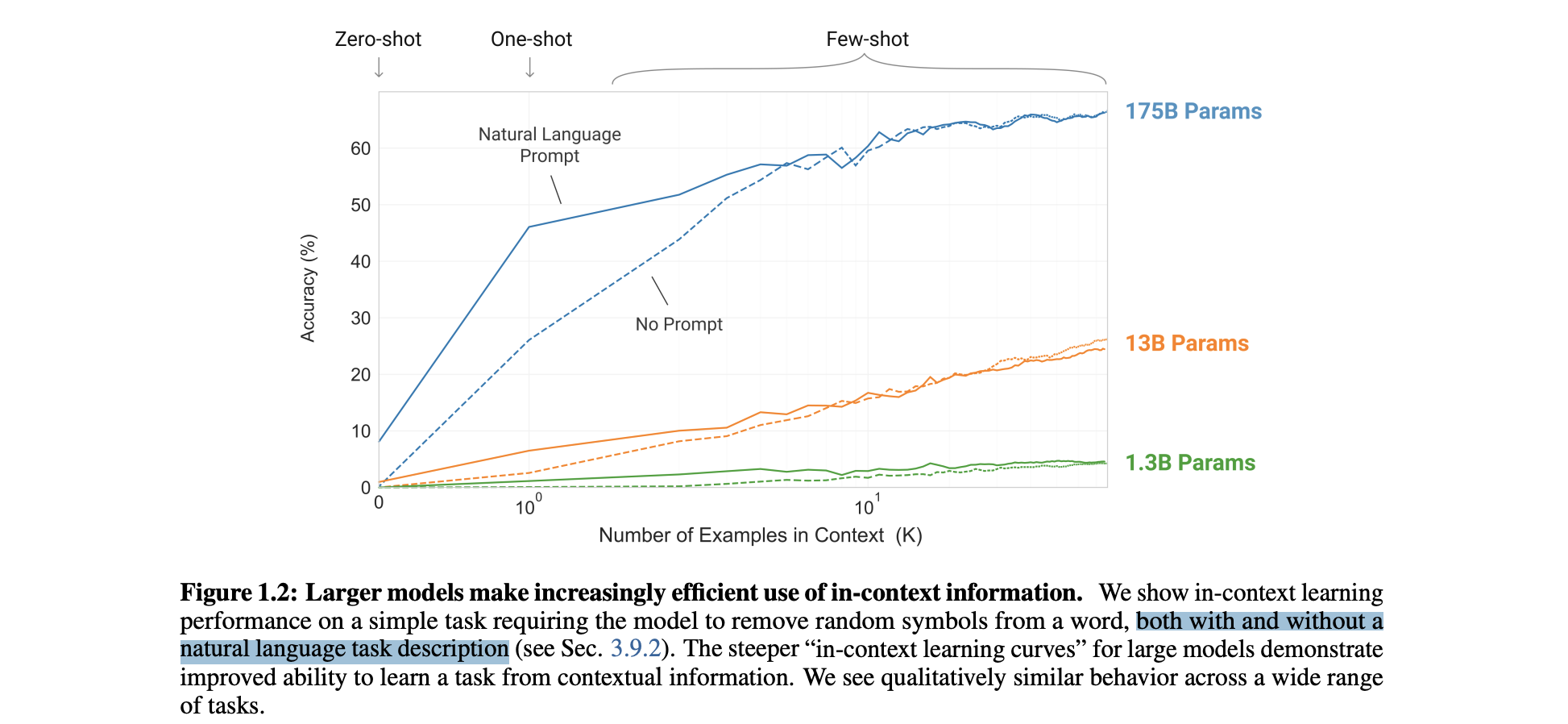
이 그림을 이해하기 위해서는 먼저 few-shot learning이 무엇인지, 그리고 언어모델에서의 few-shot learning이 무엇인지를 알아야한다.
원래의 few-shot learning이 무엇인지는 Shusen Wang 교수 영상에 매우 잘 설명되어 있다. 핵심은 "Learn-to-Learn"으로 모델이 학습할 수 있는 능력(meta-learning)을 잘 한다면, training 과정에서 한번도 학습하지 못한 데이터가 입력으로 왔을 때 support set(few shot)에서 몇개의 예시만 있다면 이를 잘 구분할 수 있다는 것이다.
언어모델에서의 few-shot learning은 바로 이 support set이 주어지는 상황을 말한다. support set의 example수가 0개면 zero-shot, 1개면 one-shot, 2개 이상이면 few-shot이라고 불리는 것인데, 중요한 것은 learning이라고 하지만 실제로는 gradient update이 일어나지 않는 과정 forward pass라는 것이다. GPT3의 input을 보면 이를 잘 이해할 수 있다.

GPT3 입력은 [task description, [SEP], examples, [SEP], prompt :]의 형태이며 출력은 prompt에 알맞은 token sequence이다. 즉, example 수가 많아지면 모델의 성능이 더 좋아지며, task description과 example들을 어떻게 주느냐가 모델의 성능에 영향을 주게 된다.
정리하자면 모델의 크기가 커지면서 few(one, zero)-shot learning의 성능이 좋아지는데 이를 설명하는 것이 in-context learning이다. stanford AI blog 글에 이러한 양상이 잘 정리되어 있다.
Informally, in-context learning describes a different paradigm of “learning” where the model is fed input normally as if it were a black box, and the input to the model describes a new task with some possible examples while the resulting output of the model reflects that new task as if the model had “learned”. While imprecise, the term is meant to capture common behaviour that was noted in the GPT-3 paper by OpenAI as a phenomenon that GPT-3 displayed with surprising consistency.
GPT3의 놀라운 점은 example이 몇개만 주어진다면 prompt에 대한 출력이 매우 안정적이며 반복적으로 알맞은 결과가 나온다는 것이다(!). 또한 이렇게 example-based conditioning 형태는 여러 태스크에 바로 적용할 수 있는 장점이 있다.
'논문 및 개념 정리' 카테고리의 다른 글
GPT 모델은 auto-regressive 모델 계열 중 하나이며 특히 GPT3는 transformer 계열 언어모델의 크기에 따른 성능을 매우 잘 보여주었다. 본 글에서는 GPT3 논문의 주요 내용 및 궁금했던 점들을 정리하고자 한다.
궁금한 점들
- in-context learning이란? & few(one, zero)-shot learning이란?
- prompt 및 GPT3 입력
더 좋은 contextualized embedding을 얻기 위한 많은 노력들 끝에 transformer 계열 모델들이 등장했다. 이후 사전학습(pre-training)된 언어모델을 사용하기 위해서 fine-tuning을 거치면 task 데이터셋에 대해서 높은 성능을 보이는 것이 확인되었으나 이는 다음과 같은 한계점들이 있다.
- task별로 fine-tuning을 위한 수만~수십만개의 데이터를 모으는 것은 비현실적임
- pre-training에서 학습한 분포와 task에서 학습한 분포와의 차이로 인해 generalization 능력이 약화되며, task 성능이 좋더라도 해당 task에만 해당되는 over-fitting된 결과일 수 있다.
- 인간은 task가 달라져도 비슷한 수준의 이해능력을 보여준다. task간 전환이 유동적이며 안정적인 성능을 보여주는 모델은 이점이 많다.
GPT3 논문은 이러한 한계점들이 극복가능한지 확인하기 위해 모델 크기에 따른 few(one, zero)-shot learning의 성능을 측정하였다.
이 그림을 이해하기 위해서는 먼저 few-shot learning이 무엇인지, 그리고 언어모델에서의 few-shot learning이 무엇인지를 알아야한다.
원래의 few-shot learning이 무엇인지는 Shusen Wang 교수 영상에 매우 잘 설명되어 있다. 핵심은 "Learn-to-Learn"으로 모델이 학습할 수 있는 능력(meta-learning)을 잘 한다면, training 과정에서 한번도 학습하지 못한 데이터가 입력으로 왔을 때 support set(few shot)에서 몇개의 예시만 있다면 이를 잘 구분할 수 있다는 것이다.
언어모델에서의 few-shot learning은 바로 이 support set이 주어지는 상황을 말한다. support set의 example수가 0개면 zero-shot, 1개면 one-shot, 2개 이상이면 few-shot이라고 불리는 것인데, 중요한 것은 learning이라고 하지만 실제로는 gradient update이 일어나지 않는 과정 forward pass라는 것이다. GPT3의 input을 보면 이를 잘 이해할 수 있다.
GPT3 입력은 [task description, [SEP], examples, [SEP], prompt :]의 형태이며 출력은 prompt에 알맞은 token sequence이다. 즉, example 수가 많아지면 모델의 성능이 더 좋아지며, task description과 example들을 어떻게 주느냐가 모델의 성능에 영향을 주게 된다.
정리하자면 모델의 크기가 커지면서 few(one, zero)-shot learning의 성능이 좋아지는데 이를 설명하는 것이 in-context learning이다. stanford AI blog 글에 이러한 양상이 잘 정리되어 있다.
Informally, in-context learning describes a different paradigm of “learning” where the model is fed input normally as if it were a black box, and the input to the model describes a new task with some possible examples while the resulting output of the model reflects that new task as if the model had “learned”. While imprecise, the term is meant to capture common behaviour that was noted in the GPT-3 paper by OpenAI as a phenomenon that GPT-3 displayed with surprising consistency.
GPT3의 놀라운 점은 example이 몇개만 주어진다면 prompt에 대한 출력이 매우 안정적이며 반복적으로 알맞은 결과가 나온다는 것이다(!). 또한 이렇게 example-based conditioning 형태는 여러 태스크에 바로 적용할 수 있는 장점이 있다.