
hugginface의 transformers 라이브러리로 만든 커스텀 모델을 onnx로 변환하고 서빙하는 과정을 정리하고자 한다. PyTorch, ONNX Runtime 튜토리얼을 참고하였으며 실제 사용 시 참고해야될 부분들을 적어두고자 한다.
0. ONNX
ONNX는 프레임워크에 종속되었던 AI, machine learning 모델들을 하나의 형식으로 통합하기 위한 오픈소스 프로젝트이다. Pytorch, Keras, TensorFlow등을 사용해 생성된 모델(연산자, parameter 집합)을 ONNX로 변환하기 위한 튜토리얼은 여기에 잘 정리되어 있다. 참고로 ONNX는 파일 포맷을 의미한다고 생각하면 되며, ONNX로 변환된 모델을 ONNX Runtime 등의 프레임워크를 통해 CPU, GPU 및 여러 하드웨어 플랫폼에서 서빙할 수 있다.
1. 커스텀 Transformers 모델 생성
(1) Transformers 기본 모델 생성 및 사용
hugginface 라이브러리 모델 레포 중 bert-base-uncased 모델을 다음과 같이 정의하여 사용할 수 있다.
from transformers import (
AutoTokenizer,
AutoModel,
BertPreTrainedModel,
BertTokenizer,
BertModel
)
model_name = "bert-base-uncased"
# model, tokenizer 정의
base_model = BertModel.from_pretrained(model_name)
base_tokenizer = BertTokenizer.from_pretrained(model_name)
# 사용 예시
text = "This is a sample text"
encoded_input = base_tokenizer(text, return_tensors='pt')
output = base_model(**encoded_input)
print(output.keys())
>>>> odict_keys(['last_hidden_state', 'pooler_output'])
print(type(output))
>>>> <class 'transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions'>
print(output.pooler_output.shape)
>>>> torch.Size([1, 768])
(2) Transformers 모델을 사용한 Custom 모델 생성
Transformers를 기반으로 커스텀 모델을 아래와 같이 생성할 수 있다(참고링크).
from transformers import (
AutoTokenizer,
AutoModel,
BertPreTrainedModel,
BertTokenizer,
BertModel
)
import torch
# Custom Model 클래스 생성
class CustomModel(torch.nn.Module):
def __init__(self, bert_model, bert_pooler_hidden_size=768, dim=10):
super(CustomModel, self).__init__()
self.bert = bert_model
self.linear = nn.Linear(bert_pooler_hidden_size, dim, bias=False)
def forward(self, input_ids, attention_mask, token_type_ids=None):
output = self.bert(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
return self.linear(output.pooler_output)
# 모델 인스턴스 생성
my_model = CustomModel(bert_model=base_model)
model_name = "bert-base-uncased"
base_tokenizer = BertTokenizer.from_pretrained(model_name)
base_model = BertModel.from_pretrained(model_name)
text = "This is a sample text"
encoded_input = base_tokenizer(text, return_tensors='pt')
print(my_model(**encoded_input))
>>>> tensor([[-0.2834, -0.6581, 0.1843, 0.0873, 0.4690, -0.0496, -0.0089, 0.3090,
-0.3761, 0.1703]], grad_fn=<MmBackward0>)
2. ONNX 변환 및 로딩
(1) ONNX 변환
위에서 새롭게 생성한 my_model을 ONNX 형식으로 변환하는 방법은 아래와 같다.
from torch.onnx import export
import torch
from torch import Tensor, device
from pathlib import Path
out_path = os.path.join('my_model_convert.onnx')
Path(out_path).parent.mkdir(parents=True, exist_ok=True)
vocab_size = base_tokenizer.vocab_size
dummy_input = (
torch.randint(vocab_size, size=[1, max_seq_length], dtype=torch.int64),
torch.ones([1, max_seq_length], dtype=torch.int64),
torch.ones([1, max_seq_length], dtype=torch.int64),
)
export(
my_model, # 실행될 모델
dummy_input, # 모델 입력값 (튜플 또는 여러 입력값들도 가능)
out_path, # 모델 저장 경로 (파일 또는 파일과 유사한 객체 모두 가능)
output_names=['output_0'], # 모델의 출력값을 가리키는 이름
input_names=[
'input_ids', 'attention_mask', 'token_type_ids'
], # 모델의 입력값을 가리키는 이름
dynamic_axes={
"input_ids": {0: "batch", 1: "sequence"},
"attention_mask": {0: "batch", 1: "sequence"},
"token_type_ids": {0: "batch", 1: "sequence"},
}, # 가변적인 길이를 가진 차원 정의
do_constant_folding=True,
opset_version=13 # 모델을 변환할 때 사용할 ONNX 버전
)이때 신경써야 할 부분은 dynamic_axes와 opset_version이다. dynamic_axes는 배치사이즈 등 크기가 고정되어 있지 않은 입력을 정의하면 되는 부분이다. opset_version은 모델 변환 시 사용할 ONNX 버전을 의미하는데 이는 PyTorch 버전마다 다르다. 정확히는 PyTorch 버전별로 지원되는 ONNX operator가 다르며, 지원되는 operator는 여기와 여기를 참고하면 된다. 간혹 error fix: onnxruntime “Type Error: Type ‘tensor(int64)’ of input parameter of operator(Min) in node is invalid’와 같은 에러가 뜨는 경우가 있는데 opset_version이 안맞아서 생기는 문제이며 버전을 올려주면 해결된다.
(2) ONNX 모델 로딩 및 inference
변환된 ONNX 모델을 CPU에서 로드하여 사용하는 방법은 다음과 같다. 주의할 부분은 저장할 때 사용한 PyTorch 버전과 로드할 때 버전이 다르면 간혹 에러가 나므로 배포환경 등을 확인해줘야 한다. CPU inference는 여기를, GPU inference는 여기를 참고하면 된다.
import onnxruntime as ort
import numpy as np
opt = ort.SessionOptions()
opt.graph_optimization_level= ort.GraphOptimizationLevel.ORT_ENABLE_EXTENDED
opt.log_severity_level=3
opt.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
ort_session = ort.InferenceSession('my_model_convert.onnx', opt)
text = "This is a sample text"
encoded_input = tokenizer(text, return_tensors='pt')
encoded_input = {name : np.atleast_2d(value) for name, value in encoded_input.items()}
print(ort_session.run(None, encoded_input)[0])
>>>> array([[-0.2833695 , -0.658051 , 0.18425903, 0.08733747, 0.46900326,
-0.04963067, -0.00891416, 0.30900627, -0.3761057 , 0.1702668 ]],
dtype=float32)
3. 속도이슈
ONNX는 CPU에서는 확실히 안정적인 성능 향상이 있다. 하지만 GPU위에서는 2배 빨라진다는 리포트도 있는 반면, 2배 느려진다는 이슈도 있다. 먼저 Tianei Wu의 블로그에서는 아래 이미지에서 처럼 CPU, GPU에서의 확실한 성능향상이 있다고 한다.

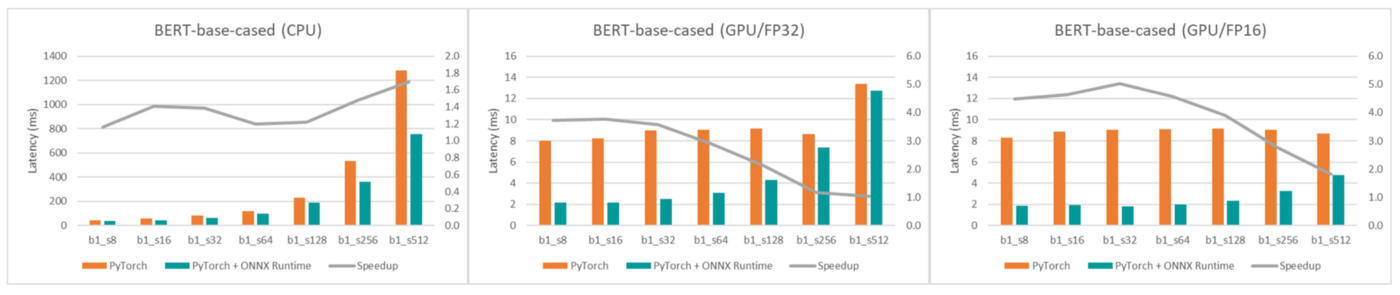
반면 onnxruntime 이슈나 stackoverflow글에서는 GPU에서 2~5배 정도 느리다는 내용도 있다. 시간 측정 이슈도 있는 것 같지만 onnxruntime + GPU 조합으로 사용 시 충분한 테스트가 필요하다.
'python 메모' 카테고리의 다른 글
| [matplotlib] 두개 그래프 y축 동시에 plot하기 (0) | 2022.10.01 |
|---|---|
| [JSON] JSON 파일 읽고 저장하고 예쁘게 프린트하기 (1) | 2022.10.01 |
| [python] Thread-Local Data (2) | 2022.08.03 |
| [pandas] duplicated()의 함정과 모든 중복 데이터 모으기 (0) | 2022.07.31 |
| [jupyter] notebook 파일 cli로 중단없이 실행시키기 (1) | 2022.07.30 |
hugginface의 transformers 라이브러리로 만든 커스텀 모델을 onnx로 변환하고 서빙하는 과정을 정리하고자 한다. PyTorch, ONNX Runtime 튜토리얼을 참고하였으며 실제 사용 시 참고해야될 부분들을 적어두고자 한다.
0. ONNX
ONNX는 프레임워크에 종속되었던 AI, machine learning 모델들을 하나의 형식으로 통합하기 위한 오픈소스 프로젝트이다. Pytorch, Keras, TensorFlow등을 사용해 생성된 모델(연산자, parameter 집합)을 ONNX로 변환하기 위한 튜토리얼은 여기에 잘 정리되어 있다. 참고로 ONNX는 파일 포맷을 의미한다고 생각하면 되며, ONNX로 변환된 모델을 ONNX Runtime 등의 프레임워크를 통해 CPU, GPU 및 여러 하드웨어 플랫폼에서 서빙할 수 있다.
1. 커스텀 Transformers 모델 생성
(1) Transformers 기본 모델 생성 및 사용
hugginface 라이브러리 모델 레포 중 bert-base-uncased 모델을 다음과 같이 정의하여 사용할 수 있다.
from transformers import (
AutoTokenizer,
AutoModel,
BertPreTrainedModel,
BertTokenizer,
BertModel
)
model_name = "bert-base-uncased"
# model, tokenizer 정의
base_model = BertModel.from_pretrained(model_name)
base_tokenizer = BertTokenizer.from_pretrained(model_name)
# 사용 예시
text = "This is a sample text"
encoded_input = base_tokenizer(text, return_tensors='pt')
output = base_model(**encoded_input)
print(output.keys())
>>>> odict_keys(['last_hidden_state', 'pooler_output'])
print(type(output))
>>>> <class 'transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions'>
print(output.pooler_output.shape)
>>>> torch.Size([1, 768])
(2) Transformers 모델을 사용한 Custom 모델 생성
Transformers를 기반으로 커스텀 모델을 아래와 같이 생성할 수 있다(참고링크).
from transformers import (
AutoTokenizer,
AutoModel,
BertPreTrainedModel,
BertTokenizer,
BertModel
)
import torch
# Custom Model 클래스 생성
class CustomModel(torch.nn.Module):
def __init__(self, bert_model, bert_pooler_hidden_size=768, dim=10):
super(CustomModel, self).__init__()
self.bert = bert_model
self.linear = nn.Linear(bert_pooler_hidden_size, dim, bias=False)
def forward(self, input_ids, attention_mask, token_type_ids=None):
output = self.bert(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
return self.linear(output.pooler_output)
# 모델 인스턴스 생성
my_model = CustomModel(bert_model=base_model)
model_name = "bert-base-uncased"
base_tokenizer = BertTokenizer.from_pretrained(model_name)
base_model = BertModel.from_pretrained(model_name)
text = "This is a sample text"
encoded_input = base_tokenizer(text, return_tensors='pt')
print(my_model(**encoded_input))
>>>> tensor([[-0.2834, -0.6581, 0.1843, 0.0873, 0.4690, -0.0496, -0.0089, 0.3090,
-0.3761, 0.1703]], grad_fn=<MmBackward0>)
2. ONNX 변환 및 로딩
(1) ONNX 변환
위에서 새롭게 생성한 my_model을 ONNX 형식으로 변환하는 방법은 아래와 같다.
from torch.onnx import export
import torch
from torch import Tensor, device
from pathlib import Path
out_path = os.path.join('my_model_convert.onnx')
Path(out_path).parent.mkdir(parents=True, exist_ok=True)
vocab_size = base_tokenizer.vocab_size
dummy_input = (
torch.randint(vocab_size, size=[1, max_seq_length], dtype=torch.int64),
torch.ones([1, max_seq_length], dtype=torch.int64),
torch.ones([1, max_seq_length], dtype=torch.int64),
)
export(
my_model, # 실행될 모델
dummy_input, # 모델 입력값 (튜플 또는 여러 입력값들도 가능)
out_path, # 모델 저장 경로 (파일 또는 파일과 유사한 객체 모두 가능)
output_names=['output_0'], # 모델의 출력값을 가리키는 이름
input_names=[
'input_ids', 'attention_mask', 'token_type_ids'
], # 모델의 입력값을 가리키는 이름
dynamic_axes={
"input_ids": {0: "batch", 1: "sequence"},
"attention_mask": {0: "batch", 1: "sequence"},
"token_type_ids": {0: "batch", 1: "sequence"},
}, # 가변적인 길이를 가진 차원 정의
do_constant_folding=True,
opset_version=13 # 모델을 변환할 때 사용할 ONNX 버전
)이때 신경써야 할 부분은 dynamic_axes와 opset_version이다. dynamic_axes는 배치사이즈 등 크기가 고정되어 있지 않은 입력을 정의하면 되는 부분이다. opset_version은 모델 변환 시 사용할 ONNX 버전을 의미하는데 이는 PyTorch 버전마다 다르다. 정확히는 PyTorch 버전별로 지원되는 ONNX operator가 다르며, 지원되는 operator는 여기와 여기를 참고하면 된다. 간혹 error fix: onnxruntime “Type Error: Type ‘tensor(int64)’ of input parameter of operator(Min) in node is invalid’와 같은 에러가 뜨는 경우가 있는데 opset_version이 안맞아서 생기는 문제이며 버전을 올려주면 해결된다.
(2) ONNX 모델 로딩 및 inference
변환된 ONNX 모델을 CPU에서 로드하여 사용하는 방법은 다음과 같다. 주의할 부분은 저장할 때 사용한 PyTorch 버전과 로드할 때 버전이 다르면 간혹 에러가 나므로 배포환경 등을 확인해줘야 한다. CPU inference는 여기를, GPU inference는 여기를 참고하면 된다.
import onnxruntime as ort
import numpy as np
opt = ort.SessionOptions()
opt.graph_optimization_level= ort.GraphOptimizationLevel.ORT_ENABLE_EXTENDED
opt.log_severity_level=3
opt.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
ort_session = ort.InferenceSession('my_model_convert.onnx', opt)
text = "This is a sample text"
encoded_input = tokenizer(text, return_tensors='pt')
encoded_input = {name : np.atleast_2d(value) for name, value in encoded_input.items()}
print(ort_session.run(None, encoded_input)[0])
>>>> array([[-0.2833695 , -0.658051 , 0.18425903, 0.08733747, 0.46900326,
-0.04963067, -0.00891416, 0.30900627, -0.3761057 , 0.1702668 ]],
dtype=float32)
3. 속도이슈
ONNX는 CPU에서는 확실히 안정적인 성능 향상이 있다. 하지만 GPU위에서는 2배 빨라진다는 리포트도 있는 반면, 2배 느려진다는 이슈도 있다. 먼저 Tianei Wu의 블로그에서는 아래 이미지에서 처럼 CPU, GPU에서의 확실한 성능향상이 있다고 한다.
반면 onnxruntime 이슈나 stackoverflow글에서는 GPU에서 2~5배 정도 느리다는 내용도 있다. 시간 측정 이슈도 있는 것 같지만 onnxruntime + GPU 조합으로 사용 시 충분한 테스트가 필요하다.
'python 메모' 카테고리의 다른 글
| [matplotlib] 두개 그래프 y축 동시에 plot하기 (0) | 2022.10.01 |
|---|---|
| [JSON] JSON 파일 읽고 저장하고 예쁘게 프린트하기 (1) | 2022.10.01 |
| [python] Thread-Local Data (2) | 2022.08.03 |
| [pandas] duplicated()의 함정과 모든 중복 데이터 모으기 (0) | 2022.07.31 |
| [jupyter] notebook 파일 cli로 중단없이 실행시키기 (1) | 2022.07.30 |