
pandas는 모든 데이터를 테이블 형태로 다루는데 엑셀에서 보기 편하게 특정 row들을 하나의 셀로 병합하여 저장하고 읽을 때가 있다.
1. row 병합 후 인덱스로 설정
ris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
not_merged = ris[['species']+ris.columns[:-1].tolist()].head()
print(not_merged.to_markdown())
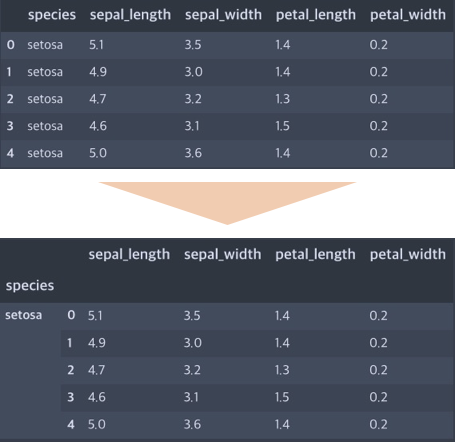
>>>> | | species | sepal_length | sepal_width | petal_length | petal_width |
|---:|:----------|---------------:|--------------:|---------------:|--------------:|
| 0 | setosa | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | setosa | 4.9 | 3 | 1.4 | 0.2 |
| 2 | setosa | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | setosa | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | setosa | 5 | 3.6 | 1.4 | 0.2 |
# cell 병합 후 set_index
merged = not_merged.set_index('species', append=True).swaplevel(1,0)
print(merged.to_markdown())
>>>> | | sepal_length | sepal_width | petal_length | petal_width |
|:--------------|---------------:|--------------:|---------------:|--------------:|
| ('setosa', 0) | 5.1 | 3.5 | 1.4 | 0.2 |
| ('setosa', 1) | 4.9 | 3 | 1.4 | 0.2 |
| ('setosa', 2) | 4.7 | 3.2 | 1.3 | 0.2 |
| ('setosa', 3) | 4.6 | 3.1 | 1.5 | 0.2 |
| ('setosa', 4) | 5 | 3.6 | 1.4 | 0.2 |
2. Excel로 읽거나 쓰기
# 쓰기
merged.to_excel('merged_example.xlsx')
# 읽기
merged = pd.read_excel('merged_example.xlsx', engine='openpyxl', index_col=[0,1])728x90
'python 메모' 카테고리의 다른 글
| [asyncio+aiohttp] 여러 API 비동기 호출 결과 얻기 (0) | 2022.02.10 |
|---|---|
| [python] ProcessPoolExecutor로 분할+병렬 연산 (0) | 2022.01.17 |
| [pandas] warning 메세지 출력 안하기 (0) | 2021.11.19 |
| [sklearn] classification_report 결과 파일로 저장하기 (0) | 2021.09.02 |
| [python] eval() 내장함수 (0) | 2021.08.29 |
pandas는 모든 데이터를 테이블 형태로 다루는데 엑셀에서 보기 편하게 특정 row들을 하나의 셀로 병합하여 저장하고 읽을 때가 있다.
1. row 병합 후 인덱스로 설정
ris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
not_merged = ris[['species']+ris.columns[:-1].tolist()].head()
print(not_merged.to_markdown())
>>>> | | species | sepal_length | sepal_width | petal_length | petal_width |
|---:|:----------|---------------:|--------------:|---------------:|--------------:|
| 0 | setosa | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | setosa | 4.9 | 3 | 1.4 | 0.2 |
| 2 | setosa | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | setosa | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | setosa | 5 | 3.6 | 1.4 | 0.2 |
# cell 병합 후 set_index
merged = not_merged.set_index('species', append=True).swaplevel(1,0)
print(merged.to_markdown())
>>>> | | sepal_length | sepal_width | petal_length | petal_width |
|:--------------|---------------:|--------------:|---------------:|--------------:|
| ('setosa', 0) | 5.1 | 3.5 | 1.4 | 0.2 |
| ('setosa', 1) | 4.9 | 3 | 1.4 | 0.2 |
| ('setosa', 2) | 4.7 | 3.2 | 1.3 | 0.2 |
| ('setosa', 3) | 4.6 | 3.1 | 1.5 | 0.2 |
| ('setosa', 4) | 5 | 3.6 | 1.4 | 0.2 |
2. Excel로 읽거나 쓰기
# 쓰기
merged.to_excel('merged_example.xlsx')
# 읽기
merged = pd.read_excel('merged_example.xlsx', engine='openpyxl', index_col=[0,1])728x90
'python 메모' 카테고리의 다른 글
| [asyncio+aiohttp] 여러 API 비동기 호출 결과 얻기 (0) | 2022.02.10 |
|---|---|
| [python] ProcessPoolExecutor로 분할+병렬 연산 (0) | 2022.01.17 |
| [pandas] warning 메세지 출력 안하기 (0) | 2021.11.19 |
| [sklearn] classification_report 결과 파일로 저장하기 (0) | 2021.09.02 |
| [python] eval() 내장함수 (0) | 2021.08.29 |