
sklearn의 classification_report는 분류 결과값을 class별로 매우 잘 뽑아준다.
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
>>>> precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
accuracy 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5결과를 정리해서 파일로 저장하고 싶어지지 않는가? 두 가지 정도 정리하고자 한다.
1. classification_report 결과 text 파일로 저장하기(★)
with open("output.txt", "w") as text_file:
print(classification_report(y_true, y_pred, digits=4), file=text_file)매우 간단하다! output.txt 파일을 열어보면 print 되었던 내용이 그대로 저장되어 있다
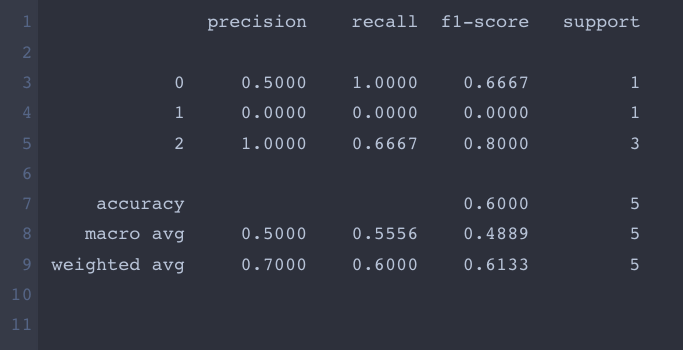
2. classification_report 결과 pandas로 변환 후 csv로 저장
csv로도 저장할 수 있다(별로 권장하지는 않는다).
from sklearn.metrics import classification_report
import pandas as pd
report = classification_report(y_true, y_pred, output_dict=True)
df = pd.DataFrame(report).transpose()
print(df)
>>>> precision recall f1-score support
0 0.5 1.000000 0.666667 1.0
1 0.0 0.000000 0.000000 1.0
2 1.0 0.666667 0.800000 3.0
accuracy 0.6 0.600000 0.600000 0.6
macro avg 0.5 0.555556 0.488889 5.0
weighted avg 0.7 0.600000 0.613333 5.0권장하지 않는 이유는 소수점 자리수를 제한해도 자기 멋대로 자리수가 늘어나고, accuracy 행의 경우 원래 precision, recall 값이 없는데 중복되서 행이 채워진다.
728x90
'python 메모' 카테고리의 다른 글
| [pandas] 특정 row들의 셀 병합하여 excel로 읽고 쓰기 (0) | 2021.11.19 |
|---|---|
| [pandas] warning 메세지 출력 안하기 (0) | 2021.11.19 |
| [python] eval() 내장함수 (0) | 2021.08.29 |
| [python] requests 라이브러리 한글 인코딩 (0) | 2021.07.27 |
| [pandas] apply + custom function을 사용한 다중 입력 및 출력 (0) | 2021.06.10 |
sklearn의 classification_report는 분류 결과값을 class별로 매우 잘 뽑아준다.
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
>>>> precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
accuracy 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5결과를 정리해서 파일로 저장하고 싶어지지 않는가? 두 가지 정도 정리하고자 한다.
1. classification_report 결과 text 파일로 저장하기(★)
with open("output.txt", "w") as text_file:
print(classification_report(y_true, y_pred, digits=4), file=text_file)매우 간단하다! output.txt 파일을 열어보면 print 되었던 내용이 그대로 저장되어 있다
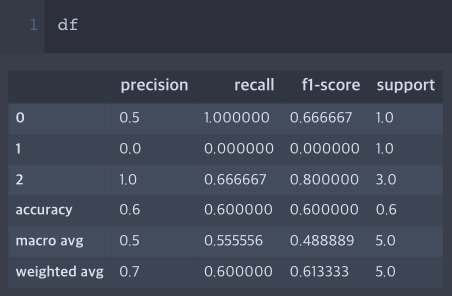
2. classification_report 결과 pandas로 변환 후 csv로 저장
csv로도 저장할 수 있다(별로 권장하지는 않는다).
from sklearn.metrics import classification_report
import pandas as pd
report = classification_report(y_true, y_pred, output_dict=True)
df = pd.DataFrame(report).transpose()
print(df)
>>>> precision recall f1-score support
0 0.5 1.000000 0.666667 1.0
1 0.0 0.000000 0.000000 1.0
2 1.0 0.666667 0.800000 3.0
accuracy 0.6 0.600000 0.600000 0.6
macro avg 0.5 0.555556 0.488889 5.0
weighted avg 0.7 0.600000 0.613333 5.0권장하지 않는 이유는 소수점 자리수를 제한해도 자기 멋대로 자리수가 늘어나고, accuracy 행의 경우 원래 precision, recall 값이 없는데 중복되서 행이 채워진다.
728x90
'python 메모' 카테고리의 다른 글
| [pandas] 특정 row들의 셀 병합하여 excel로 읽고 쓰기 (0) | 2021.11.19 |
|---|---|
| [pandas] warning 메세지 출력 안하기 (0) | 2021.11.19 |
| [python] eval() 내장함수 (0) | 2021.08.29 |
| [python] requests 라이브러리 한글 인코딩 (0) | 2021.07.27 |
| [pandas] apply + custom function을 사용한 다중 입력 및 출력 (0) | 2021.06.10 |