
문서분류 task와 관련해서 진행한 내용을 정리하고자 한다.
0. Task 정의
Task는 다음과 같았다.
- Long Document: 길이가 긴 문서 상황에서 효과적인 모델 찾기
- Class Imbalance: class 분포가 극도로 불균형한 상황에서의 성능향상 기법
1) Long Document
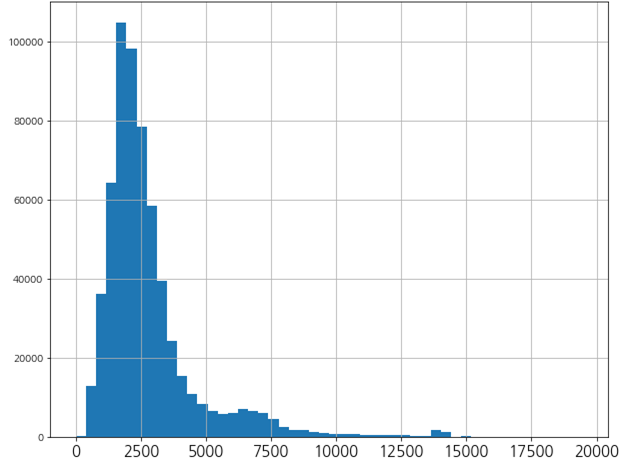
PoC에서 다루었던 문서의 길이는 매우 긴편이었다. mecab 기준 평균 2,500 token이 넘었으며 길면 20,000 token도 넘는 문서가 있었다.
2) Class Imbalance
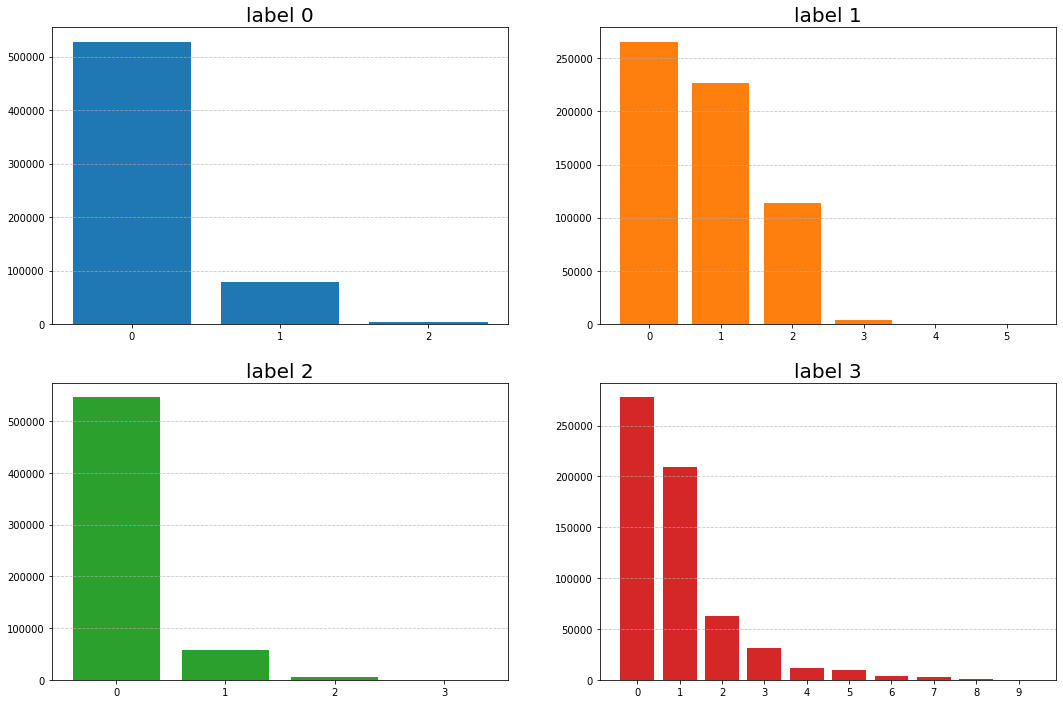
다루었던 문서는 총 4개의 label이 있었으며 label별 class들의 분포가 매우 불균형한 데이터였다.
1. Long Document에 대한 효과적인 모델 찾기
첫번째 task를 위해서 총 3가지 모델을 비교하였다.
1) AutoGluon
AutoGluon은 AutoML 오픈소스로, tabular prediction / image prediction / object detection / text prediction 기능을 담고 있으며, 현재 포스팅 기준 0.2.1(dev), 0.2.0(stable)까지 릴리즈 되어있다.(AutoGluon 문서)
PoC 수행시 0.0.15 버전이 최신이었는데, text-predictor의 경우 모델 학습 결과에 대한 해석이 제공이 안되고 추론 기능도 불안정하여 tabular-predictor를 사용하였다. tabular-predictor는 여러 classfier를 순차적으로 학습하여 앙상블한다. text-predictor는 pre-train된 BERT, ALBERT 등의 모델로 사용자의 데이터에 대해 transfer learning하여 classifier를 학습시킨다.
tabular-predictor에 숫자가 아닌 문서를 입력으로 넣을 경우 Bag of Words(BoW)로 vectorization한 후 random forest classifier, extra trees classifier, light GBM classifier 등 10여개의 모델을 앙상블한다.
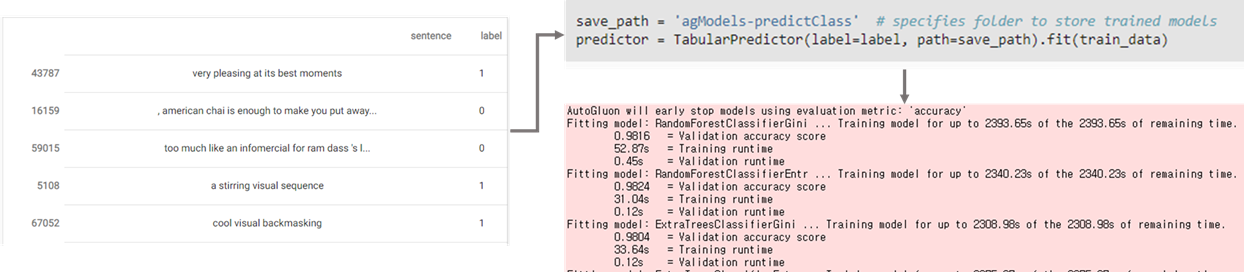
모델의 학습은 입력 형태만 pandas등으로 document/label 데이터만 넣어주면 keras와 비슷하게 fit 하나만 호출하여 학습할 수 있다.
2) MPAD(Message Passing Attention networks for Document understanding)
MPAD 모델은 문서를 token 단위로 그래프화한 후 문서 embedding을 계산하는 모델이다. 먼저 단어들 간의 co-occurrence graph를 구성하고 word2vec을 학습하여 노드(token)의 임베딩을 초기화한다. 이후 message passing을 사용하는데 passing step을 한번 거칠 때 마다 각 노드는 neighbor node로부터의 incoming edge들의 weighted average로 업데이트가 왼다. 이후 GRU를 사용하여 이전 time stamp들의 embedding을 결합하여 최종적으로 문서 embedding을 얻는다.(MPAD 논문)
3) BERT
BERT는 transformer encoder 기반의 언어모델이며, Enliple사의 BERT를 사용하였다(Enlipleai github). 문서의 길이가 매우 길기 때문에 각 문서를 512 token 단위로 자르고 BERT를 태운 [CLS] token의 embedding을 concat하여 max-pool 방식을 통해 embedding을 얻고 분류하도록 학습하였다.
4) 성능비교
길이가 긴 문서에 대해서는 AutoGluon, MPAD가 BERT보다 성능이 좋음을 확인할 수 있다. 특히 minority class 분류에 대해서는 AutoGluon과 같이 weak classifier를 여러 개 ensemble한 모델의 성능이 매우 좋았다.


2. Class Imbalance 상황에서의 성능 향상
class의 분포가 극도로 불균형한 상황에서 적용시킬 수 있는 방법들을 소개하고 PoC에 사용한 방법과 결과를 정리하고자 한다. 실험 및 성능비교는 MPAD를 기준으로 진행하였다.
1) Sampling
Sampling 방법으로는
- under-sampling: majority class 중 일부만 sampling하여 minority 수와 비슷하게 분포를 맞춤
- over-sampling: minority class를 중복 sampling하여 수를 늘림
- weighted-sampling: 각 batch 학습 시 원래 class 분포대로 sampling하여 학습
와 같은 방법들이 있다. under-sampling은 존재하는 데이터를 훼손하는 점, weighted-sampling은 예전에 적용시 성능향상이 없었다는 점에서 제외하였으며, over-sampling 방식으로 PoC를 진행하였다. 구체적으로는 minority class를 명시적으로 모델에게 알려주며, minority class들이 이들을 제외한 class들 중 최소값이 되도록 random sampling하였다.
| class 별 개수 | |
| over-sampling 전 | 0: 4527, 1: 379, 2: 643, 3: 40520, 4: 39, 5: 30583, 6: 1394, 7: 180, 8: 1715, 9: 9052 |
| over-sampling 후 | 0: 4527, 1: 379, 2: 643, 3: 40520, 4: 379, 5: 30583, 6: 1394, 7: 379, 8: 1715, 9: 9052 |
2) Synthetic Data Generation
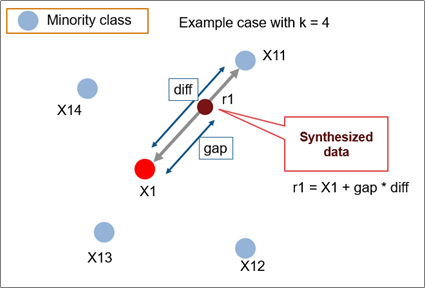
인위적으로 데이터를 생성하여 Data Augmentation도 많이 사용된 방법이다. 기존에는 SMOTE(2002) 논문에서 제안된 방식을 많이 사용하였는데, 이는 feature space 상에서 minority class 데이터 사이의 선분에서 임의로 포인트를 선택하여 데이터 포인트 수를 늘리는 방법이다. 이 방법은 discriminative 모델들이 decision boundary를 더 잘 찾을 수 있게 해주는 것으로 알려져있다.
본 PoC에서는 GAN을 활용하여 synthetic data를 만드는 $Generator$를 학습시켰다. 매우 뛰어나신 분이 제안해주신 아이디어였는데 찾아보니 최근에 논문으로도 발표된 아이디어였다(MFC-GAN(2019), Capsule-Discriminator(2020)). $Generator$는 class id를 입력으로 받아 각 class별 임베딩을 계산하며, $Discriminator$는 real, fake를 구분하거나 real class id, fake class id를 구분하도록 학습시킨다. 이후 classifier를 학습 시 각 batch samling에서 $Generator$가 부족한 class id들에 대한 embedding을 생성하여 class별 분포를 동일하게 맞춰준다.
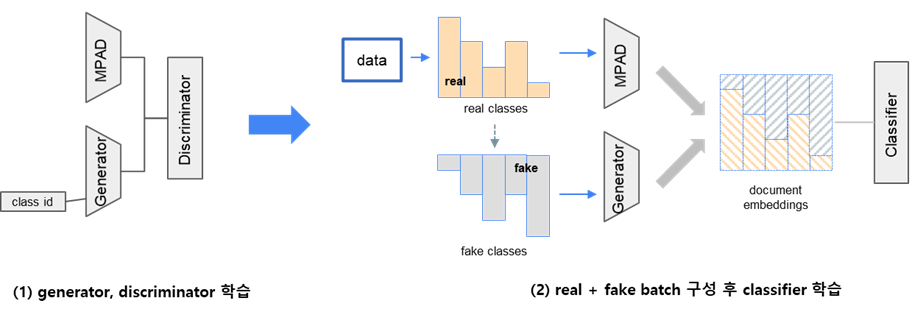
3) Cost 부여
어떤 embedding 모델을 classifier와 함께 학습시킨다고 하였을 때, class id를 같이 입력으로 준다면 classifier가 다른 class를 예측했을 때 cost를 줄 수가 있다. 만약 minority class에 대해 majority class로 예측을 한다면 더 큰 cost를 줘서 embedding 모델이 minority class에 대해서도 embedding을 잘 학습하는 효과를 줄 수가 있다.(Cost-Sensitive Learning(2018))
기존에는 이런 cost를 전문가의 경험을 통해 직접 줬었는데, trainable parameter로 둔다면 이를 classifier와 함께 학습시킬 수 있다. PoC는 이러한 아이디어를 기반으로 수행하였으며, MPAD 모델을 학습시키는 단계와 cost matrix를 학습시키는 단계를 번갈아가며 학습하였다.
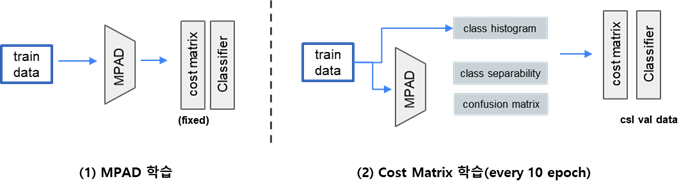
4) 성능비교
실험 결과 over-sampling 방법의 성능 향상이 제일 좋았다. 워낙 데이터 등장 횟수가 적었기 때문에 조금만 더 데이터 수를 늘려줘도 성능 향상이 있던 것 같다. 아래 그림에서 주황색은 MPAD 계열 성능보다도 AutoGluon의 성능이 더 좋음을 의미하고, 초록색은 MPAD 계열 성능 중 최대값임을 의미한다.

'Toy Projects' 카테고리의 다른 글
| [LM] 언어모델 학습기 (0) | 2022.04.05 |
|---|---|
| [연구] 분류 Class가 많을 때 Softmax 개선 방법 (0) | 2021.12.20 |
| Selenium를 활용한 PAPAGO 번역 사용기 (0) | 2020.06.07 |
문서분류 task와 관련해서 진행한 내용을 정리하고자 한다.
0. Task 정의
Task는 다음과 같았다.
- Long Document: 길이가 긴 문서 상황에서 효과적인 모델 찾기
- Class Imbalance: class 분포가 극도로 불균형한 상황에서의 성능향상 기법
1) Long Document
PoC에서 다루었던 문서의 길이는 매우 긴편이었다. mecab 기준 평균 2,500 token이 넘었으며 길면 20,000 token도 넘는 문서가 있었다.
2) Class Imbalance
다루었던 문서는 총 4개의 label이 있었으며 label별 class들의 분포가 매우 불균형한 데이터였다.
1. Long Document에 대한 효과적인 모델 찾기
첫번째 task를 위해서 총 3가지 모델을 비교하였다.
1) AutoGluon
AutoGluon은 AutoML 오픈소스로, tabular prediction / image prediction / object detection / text prediction 기능을 담고 있으며, 현재 포스팅 기준 0.2.1(dev), 0.2.0(stable)까지 릴리즈 되어있다.(AutoGluon 문서)
PoC 수행시 0.0.15 버전이 최신이었는데, text-predictor의 경우 모델 학습 결과에 대한 해석이 제공이 안되고 추론 기능도 불안정하여 tabular-predictor를 사용하였다. tabular-predictor는 여러 classfier를 순차적으로 학습하여 앙상블한다. text-predictor는 pre-train된 BERT, ALBERT 등의 모델로 사용자의 데이터에 대해 transfer learning하여 classifier를 학습시킨다.
tabular-predictor에 숫자가 아닌 문서를 입력으로 넣을 경우 Bag of Words(BoW)로 vectorization한 후 random forest classifier, extra trees classifier, light GBM classifier 등 10여개의 모델을 앙상블한다.
모델의 학습은 입력 형태만 pandas등으로 document/label 데이터만 넣어주면 keras와 비슷하게 fit 하나만 호출하여 학습할 수 있다.
2) MPAD(Message Passing Attention networks for Document understanding)
MPAD 모델은 문서를 token 단위로 그래프화한 후 문서 embedding을 계산하는 모델이다. 먼저 단어들 간의 co-occurrence graph를 구성하고 word2vec을 학습하여 노드(token)의 임베딩을 초기화한다. 이후 message passing을 사용하는데 passing step을 한번 거칠 때 마다 각 노드는 neighbor node로부터의 incoming edge들의 weighted average로 업데이트가 왼다. 이후 GRU를 사용하여 이전 time stamp들의 embedding을 결합하여 최종적으로 문서 embedding을 얻는다.(MPAD 논문)
3) BERT
BERT는 transformer encoder 기반의 언어모델이며, Enliple사의 BERT를 사용하였다(Enlipleai github). 문서의 길이가 매우 길기 때문에 각 문서를 512 token 단위로 자르고 BERT를 태운 [CLS] token의 embedding을 concat하여 max-pool 방식을 통해 embedding을 얻고 분류하도록 학습하였다.
4) 성능비교
길이가 긴 문서에 대해서는 AutoGluon, MPAD가 BERT보다 성능이 좋음을 확인할 수 있다. 특히 minority class 분류에 대해서는 AutoGluon과 같이 weak classifier를 여러 개 ensemble한 모델의 성능이 매우 좋았다.
2. Class Imbalance 상황에서의 성능 향상
class의 분포가 극도로 불균형한 상황에서 적용시킬 수 있는 방법들을 소개하고 PoC에 사용한 방법과 결과를 정리하고자 한다. 실험 및 성능비교는 MPAD를 기준으로 진행하였다.
1) Sampling
Sampling 방법으로는
- under-sampling: majority class 중 일부만 sampling하여 minority 수와 비슷하게 분포를 맞춤
- over-sampling: minority class를 중복 sampling하여 수를 늘림
- weighted-sampling: 각 batch 학습 시 원래 class 분포대로 sampling하여 학습
와 같은 방법들이 있다. under-sampling은 존재하는 데이터를 훼손하는 점, weighted-sampling은 예전에 적용시 성능향상이 없었다는 점에서 제외하였으며, over-sampling 방식으로 PoC를 진행하였다. 구체적으로는 minority class를 명시적으로 모델에게 알려주며, minority class들이 이들을 제외한 class들 중 최소값이 되도록 random sampling하였다.
| class 별 개수 | |
| over-sampling 전 | 0: 4527, 1: 379, 2: 643, 3: 40520, 4: 39, 5: 30583, 6: 1394, 7: 180, 8: 1715, 9: 9052 |
| over-sampling 후 | 0: 4527, 1: 379, 2: 643, 3: 40520, 4: 379, 5: 30583, 6: 1394, 7: 379, 8: 1715, 9: 9052 |
2) Synthetic Data Generation
인위적으로 데이터를 생성하여 Data Augmentation도 많이 사용된 방법이다. 기존에는 SMOTE(2002) 논문에서 제안된 방식을 많이 사용하였는데, 이는 feature space 상에서 minority class 데이터 사이의 선분에서 임의로 포인트를 선택하여 데이터 포인트 수를 늘리는 방법이다. 이 방법은 discriminative 모델들이 decision boundary를 더 잘 찾을 수 있게 해주는 것으로 알려져있다.
본 PoC에서는 GAN을 활용하여 synthetic data를 만드는
3) Cost 부여
어떤 embedding 모델을 classifier와 함께 학습시킨다고 하였을 때, class id를 같이 입력으로 준다면 classifier가 다른 class를 예측했을 때 cost를 줄 수가 있다. 만약 minority class에 대해 majority class로 예측을 한다면 더 큰 cost를 줘서 embedding 모델이 minority class에 대해서도 embedding을 잘 학습하는 효과를 줄 수가 있다.(Cost-Sensitive Learning(2018))
기존에는 이런 cost를 전문가의 경험을 통해 직접 줬었는데, trainable parameter로 둔다면 이를 classifier와 함께 학습시킬 수 있다. PoC는 이러한 아이디어를 기반으로 수행하였으며, MPAD 모델을 학습시키는 단계와 cost matrix를 학습시키는 단계를 번갈아가며 학습하였다.
4) 성능비교
실험 결과 over-sampling 방법의 성능 향상이 제일 좋았다. 워낙 데이터 등장 횟수가 적었기 때문에 조금만 더 데이터 수를 늘려줘도 성능 향상이 있던 것 같다. 아래 그림에서 주황색은 MPAD 계열 성능보다도 AutoGluon의 성능이 더 좋음을 의미하고, 초록색은 MPAD 계열 성능 중 최대값임을 의미한다.
'Toy Projects' 카테고리의 다른 글
| [LM] 언어모델 학습기 (0) | 2022.04.05 |
|---|---|
| [연구] 분류 Class가 많을 때 Softmax 개선 방법 (0) | 2021.12.20 |
| Selenium를 활용한 PAPAGO 번역 사용기 (0) | 2020.06.07 |