
대량의 영어 데이터를 한글로 번역할 일이 있었는데 구글은 퀄리티가 떨어져 도저히 사용할 수 없었습니다. 네이버 PAPAGO를 써보니 한글은 꽤 준수하게 번역이 되어서 3만개가 넘는 문장을 PAPAGO로 번역하기로 결정했어요.
PAPAGO API는 일 1만자 밖에 번역이 안되고 API 제휴 신청하기에는 1회성으로 사용하는거라 신청할 수 없는 상황이었어요. 누가 Selenium을 말해줘서 사용해봤구 성공적으로 번역을 마칠 수 있어서 사용기를 남기려 합니다.
0. Selenium이란?
(참고링크) Selenium은 Webdriver를 사용하여 웹앱을 테스트할 수 있는 도구입니다. Request의 경우 단순히 정적인 HTML만 가져오는 것에 비해, Selenium은 웹브라우저 자체에서 동작하므로 Javascript의 기능 등을 테스트해볼 수 있습니다.
1. Selenium 활용을 위한 작업환경 세팅(Chrome 기준)
OS: MacOS Catalina
언어: Python3 + Jupyter Notebook
웹 브라우저: Chrome
작업파일: boolq data의 train.jonl 파일
먼저 이 링크에서 크롬 웹브라우저 드라이버를 받아줍니다. 버전은 사용자에게 설치된 버전으로 받아야 하며, 사용자의 크롬 버전 확인은 주소창에 chrome://version을 입력해주면 알 수 있습니다. 제 크롬 버전은 83.0.4103.61 이네요.

WebDriver도 83.0 버전으로 받아주도록 하겠습니다.

다운 받은 파일의 압축을 풀어주고 작업할 디렉토리에 옮겨줍니다. 코드를 작성할 파일은 드라이버와 같은 디렉토리에 두도록 하겠습니다.

Terminal을 키고 아래 명령어로 Selenium을 설치해주고 Jupyter Notebook을 실행시킵니다.
pip install selenium
2. Selenium을 활용하여 영어 문장 PAPAGO로 번역
selenium의 webdriver를 import해줍니다.
form selenium import webdriver
데이터를 load해서 list 안에 담아두겠습니다.
all_data = []
with jsonlines.open('train.jsonl') as reader:
for obj in reader:
all_data.append(obj)
len(all_data)
selenium이 컨트롤할 웹브라우저를 webdriver를 사용해서 띄워줍니다. 확인되지 않은 개발자라고 뜬다면 '시스템 환경설정 - 보안 및 개인 정보 보호'로 들어가면 하단에 chromedriver를 허용하겠냐는 메시지가 떠있습니다. 확인 버튼을 눌러주고 아래 코드를 실행시키면 'Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.'라는 문구가 적힌 크롬 브라우저가 뜹니다.
driver = webdriver.Chrome('./chromedriver')
driver.get('https://papago.naver.com')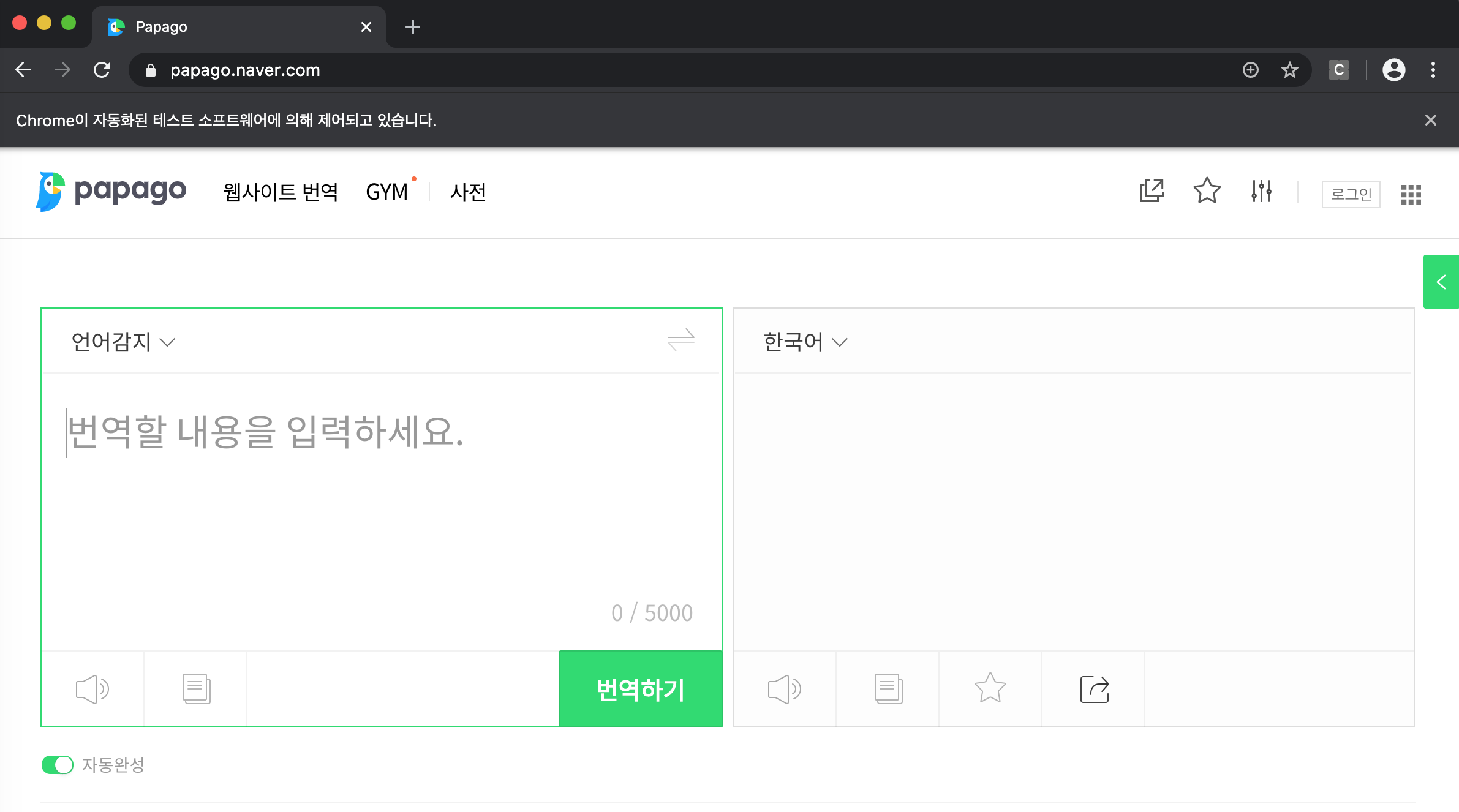
이제 번역할 텍스트를 날려보겠습니다. 전체 번역 과정은
1) 번역 텍스트 입력
2) '번역하기' 버튼 클릭
3) 번역된 텍스트 가져오기
4) X표시를 눌러 번역 텍스트 입력란 초기화
4)번과 같이 초기화 하는 이유는 네트워크 환경, 텍스트 길이의 차이 등으로 인해 이전에 텍스트가 새롭게 입력되더라도 번역이 완료가 안되 이전 텍스트의 번역이 불러와지는 경우가 있기 때문입니다. 또한 sleep()을 걸어주어 충분히 번역될 수 있는 시간을 마련해줍니다.
동작하는 화면은 다음과 같습니다.

1), 2), 3)에 해당되는 HTML element를 지정해줘야 하며, 다음과 같지 지정할 수 있습니다.
input_box = driver.find_element_by_css_selector('textarea#txtSource')
button = driver.find_element_by_css_selector('button#btnTranslate')
x_button = driver.find_element_by_class_name('btn_text_clse___1Bp8a')
train.jsonl 데이터가 question, passage로 이루어져 있는데 길이 차이가 굉장히 많이 납니다. 문장 길이와 네트워크 환경으로 인해 번역된 데이터가 겹칠 수 있어서 이를 확인하기 위한 함수를 만들어서 사용했습니다.
def qp_asserting(_q, _p, idx):
if _q != _p:
return True
else:
print('경찰아저씨 여기에요!!! ', str(idx))
return False
번역된 데이터와 예외 처리 된 데이터 index를 저장할 리스트를 따로 만들어줍니다.
results_train = []
skipped_idx_train = []
전체코드는 아래와 같습니다. 완료되려면 꽤 오래걸리기 때문에 중간에 pickle로 저장해두도록 했습니다.
from selenium import webdriver
import time
import os
import jsonlines
import pickle
# 데이터 import
all_data = []
with jsonlines.open('train.jsonl') as reader:
for obj in reader:
all_data.append(obj)
# 브라우저 실행
driver = webdriver.Chrome('./chromedriver')
driver.get('https://papago.naver.com')
# HTML selector 선택
input_box = driver.find_element_by_css_selector('textarea#txtSource')
button = driver.find_element_by_css_selector('button#btnTranslate')
x_button = driver.find_element_by_class_name('btn_text_clse___1Bp8a')
# 번역 중복방지 확인 함수
def qp_asserting(_q, _p, idx):
if _q != _p:
return True
else:
print('경찰아저씨 여기에요!!! ', str(idx))
return False
# 번역 진행
results_train = []
skipped_idx_train = []
dir_name = 'results_train'
filename_suffix = 'pkl'
_work_from_idx = 0
for idx, data in enumerate(all_data[_work_from_idx:]):
_idx = idx + _work_from_idx
print('WORKING ON IDX ======================', _idx)
try:
_result = {}
_q_result = None
_p_result = None
# question
input_box.clear()
input_box.send_keys(data['question']+'?')
button.click()
time.sleep(4)
_q_result = driver.find_element_by_css_selector('div#txtTarget').text
print('_q_result:: ', _q_result)
_result['question'] = _q_result
# passage
input_box.clear()
input_box.send_keys(data['passage'])
button.click()
time.sleep(6)
_p_result = driver.find_element_by_css_selector('div#txtTarget').text
print('_p_result:: ', _p_result[:130])
_result['passage'] = _p_result
qp_flag = qp_asserting(_q_result, _p_result, _idx)
if not qp_flag:
skipped_idx_train.append(_idx)
_result['answer'] = data['answer']
# if len(_q_result) > len(_p_result):
# print('ERROR OCCURED IDX [*]', idx)
# break
_result['answer'] = data['answer']
# ================================= #
results_train.append(_result)
x_button.click()
time.sleep(np.random.randint(3))
except Exception as e:
print('='*30)
print('ERROR IDX::::::: ', _idx, '\n', 'EROR IS :::::::',e)
skipped_idx_train.append(_idx)
continue
if (_idx+1)%500 == 0:
base_filename = 'results_'+str(_idx+1)
save_file = os.path.join(dir_name, base_filename + "." + filename_suffix)
with open(save_file, 'wb') as f:
pickle.dump(results, f)
print(skipped_idx)
'Toy Projects' 카테고리의 다른 글
| [LM] 언어모델 학습기 (0) | 2022.04.05 |
|---|---|
| [연구] 분류 Class가 많을 때 Softmax 개선 방법 (0) | 2021.12.20 |
| [문서분류 PoC] Long Document & Class Imbalance (0) | 2021.05.20 |