
GPT3와 같이 매우 큰 언어모델을 서비스 목적에 맞게 fine-tuning하는 것은 비용도 클 뿐더러 성능이 안정적이지 않을 수 있다. 이런 fine-tuning을 효율적으로 하기 위해 p-tuning, LoRA와 같은 방법들이 소개가 되었다. 개인적으로는 p-tuning이 개발기간도 짧고 안정적인 성능향상이 있기 때문에 더 선호하는데 이를 정리해보고자 한다.(논문링크)(공개소스)
1. Introduction
언어모델은 다음과 같이 크게 3종류가 있다.
- unidirectional LM(a.k.a auto-regressive model): GPT 계열
- bidirectional LM: BERT 계열
- hybrid LM: XLNet, UniLM
GPT 계열의 단점은 NLU 태스크(NLI, AE 등)에서 성능이 떨어질 뿐만 아니라 좋은 성능을 내는 HEAD+examples+prompt 조합을 찾는 과정(prompt-engineering)이 까다롭다는 것이다.
본 논문에서 제안하는 P-tuning은 prompt가 discrete space에서 prompt를 찾는 과정에서 벗어나 continuous space상에서 존재하도록하는 방법이다. Discrete space라 함은 사람이 일일히 자연어 문장을 입력하기 때문에 입력 token에 대해 discrete함을 의미하고, P-tuning에서는 trainable parameter를 둬서 입력 token space를 continuous space로 옮겨주는 역할을 한다.
2. Method
먼저 용어를 정리해보면 아래와 같다.
- Language Model: $M$
- discrete input tokens: $x_{1:n} = \{x_{0}, x_{1}, \cdots, x_{n}\}$
- input embeddings: $ \{e(x_{0}), e(x_{1}), \cdots, e(x_{n}) \}$
- vocabulary of Language Model: $V$
- i-th prompt token: $[P_{i}]$
LM이 학습되는 시나리오는 input token $x$에 대해 target $y$를 맞추는 것이다. BERT의 경우 $y$는 [MASK] token, GPT의 경우 next token이 될 것이다.
이때 prompt $p$의 역할을 context $x$, target $y$와 prompt를 엮어 template $T$로 만드는 것으로 정의해볼 수 있다. 아래 그림에서 처럼 "The capital of Britain is [MASK]."이라는 template이 있을 때 "The capital of ... is ... ."가 prompt, "Britain"이 context, "[MASK]"가 target이 된다.
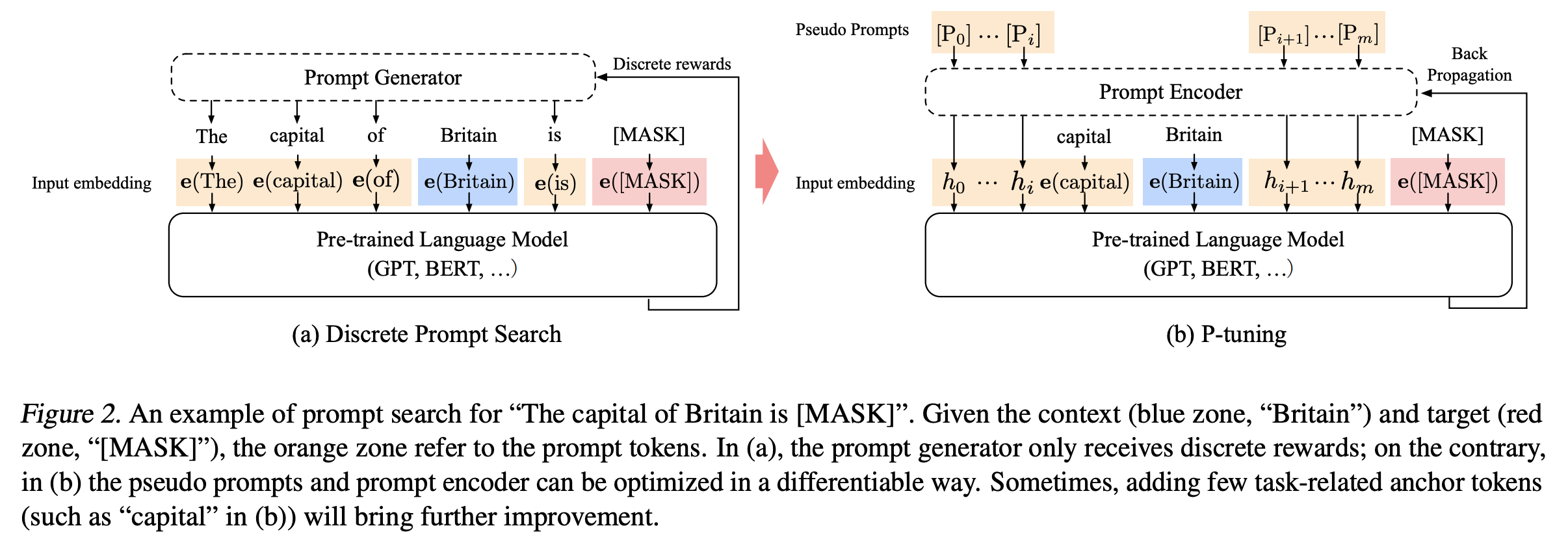
조금 헷갈렸던 부분은 prompt의 위치와 개수였는데 공개된 코드에서 확인해보니 input token 앞뒤로 3개씩 붙여주는 등 고정된 위치에 적절한 개수(10개 내외)를 주는 것 같다.
위의 그림 기준으로 설명해보면 input을 template $T = \{[P_{0:i}], x, [P_{i+1:m}],y \}$라고 할때, 원래의 언어모델은 $[P_{i}] \in V$이고 $T$을 아래와 같이 임베딩을 계산한다.
$$\{ e([P_{0:i}]), e(x), e([P_{i+1:m}]), e(y) \}$$
하지만 P-tuning에서는 $[P_{i}]$를 pseudo token으로 가정하고 아래와 같이 임베딩을 계산한다.
$$\{ h_{0},..., h_{i} , e(x), h_{i+1},...,h_{m}, e(y) \}$$
여기서 $h_{i}$는 trainable embedding tensor(Prompt Encoder output)로 논문의 설명대로라면 원래의 언어모델 $M$이 표현할 수 있는 vocabulary $V$의 한계를 넘어 continuous space상에서 존재하는 prompt를 얻을 수 있게 된다고 한다.
그 이후에는 언어모델 $M$의 parameter는 고정시켜두고 원래의 loss function $L$을 사용하여 continuous prompt $h_{i}(0\le i \lt m)$ 미분을 통해 optimize한다.
$$\hat{h}_{0:m} = \underset{h}{arg \ min} \ L(M(x,y))$$
Prompt Encoder로는 LSTM을 사용했다고 하는데 간단한 MLP를 사용해도 무방하다.
3. Experiments
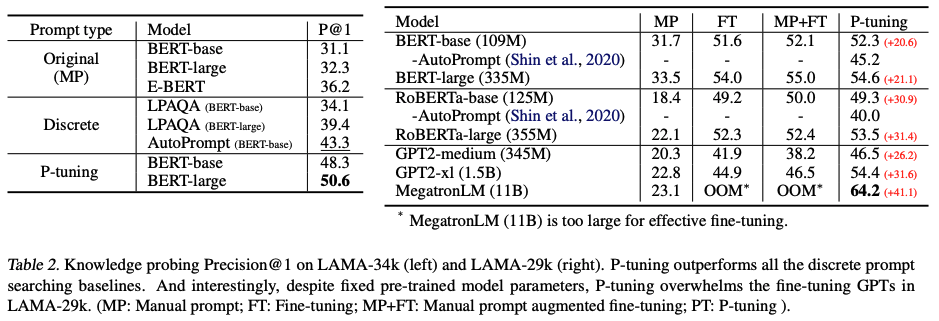
P-tuning이 왜 많이 쓰이는지를 보여주는 실험 결과이다. GPT, BERT 계열에서 fine-tuning을 통해 많은 성능 향상을 끌어냈으며 언어모델 구조와 상관없이 적용이 가능하다. 오른쪽 결과는 Manual Prompt(MP), Fine-tuning(FT), MP+FT, P-tuning의 성능을 비교한 것인데 Fine-tuning보다 같거나 더 좋은 결과를 보여주고 있다.
'논문 및 개념 정리' 카테고리의 다른 글
| [2022] SimCSE: Simple Contrastive Learning of Sentence Embeddings (0) | 2022.10.01 |
|---|---|
| [2021] LoRA: Low-Rank Adaptation of Large Language Models (0) | 2022.07.14 |
| [2020] Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring (0) | 2022.04.04 |
| [LM] Perplexity 개념 (0) | 2022.02.17 |
| [GPT3] 주요 내용 정리 (0) | 2022.02.16 |
GPT3와 같이 매우 큰 언어모델을 서비스 목적에 맞게 fine-tuning하는 것은 비용도 클 뿐더러 성능이 안정적이지 않을 수 있다. 이런 fine-tuning을 효율적으로 하기 위해 p-tuning, LoRA와 같은 방법들이 소개가 되었다. 개인적으로는 p-tuning이 개발기간도 짧고 안정적인 성능향상이 있기 때문에 더 선호하는데 이를 정리해보고자 한다.(논문링크)(공개소스)
1. Introduction
언어모델은 다음과 같이 크게 3종류가 있다.
- unidirectional LM(a.k.a auto-regressive model): GPT 계열
- bidirectional LM: BERT 계열
- hybrid LM: XLNet, UniLM
GPT 계열의 단점은 NLU 태스크(NLI, AE 등)에서 성능이 떨어질 뿐만 아니라 좋은 성능을 내는 HEAD+examples+prompt 조합을 찾는 과정(prompt-engineering)이 까다롭다는 것이다.
본 논문에서 제안하는 P-tuning은 prompt가 discrete space에서 prompt를 찾는 과정에서 벗어나 continuous space상에서 존재하도록하는 방법이다. Discrete space라 함은 사람이 일일히 자연어 문장을 입력하기 때문에 입력 token에 대해 discrete함을 의미하고, P-tuning에서는 trainable parameter를 둬서 입력 token space를 continuous space로 옮겨주는 역할을 한다.
2. Method
먼저 용어를 정리해보면 아래와 같다.
- Language Model:
- discrete input tokens:
- input embeddings:
- vocabulary of Language Model:
- i-th prompt token:
LM이 학습되는 시나리오는 input token
이때 prompt
조금 헷갈렸던 부분은 prompt의 위치와 개수였는데 공개된 코드에서 확인해보니 input token 앞뒤로 3개씩 붙여주는 등 고정된 위치에 적절한 개수(10개 내외)를 주는 것 같다.
위의 그림 기준으로 설명해보면 input을 template
하지만 P-tuning에서는
여기서
그 이후에는 언어모델
Prompt Encoder로는 LSTM을 사용했다고 하는데 간단한 MLP를 사용해도 무방하다.
3. Experiments
P-tuning이 왜 많이 쓰이는지를 보여주는 실험 결과이다. GPT, BERT 계열에서 fine-tuning을 통해 많은 성능 향상을 끌어냈으며 언어모델 구조와 상관없이 적용이 가능하다. 오른쪽 결과는 Manual Prompt(MP), Fine-tuning(FT), MP+FT, P-tuning의 성능을 비교한 것인데 Fine-tuning보다 같거나 더 좋은 결과를 보여주고 있다.
'논문 및 개념 정리' 카테고리의 다른 글
| [2022] SimCSE: Simple Contrastive Learning of Sentence Embeddings (0) | 2022.10.01 |
|---|---|
| [2021] LoRA: Low-Rank Adaptation of Large Language Models (0) | 2022.07.14 |
| [2020] Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring (0) | 2022.04.04 |
| [LM] Perplexity 개념 (0) | 2022.02.17 |
| [GPT3] 주요 내용 정리 (0) | 2022.02.16 |