
Information retrieval이나 question answering 모델을 구성할 때 매우 큰 search space에서 속도와 성능이 둘다 중요한데 이를 위해 Retrieval & Rerank 구조가 많이 쓰인다(SBERT 설명글).
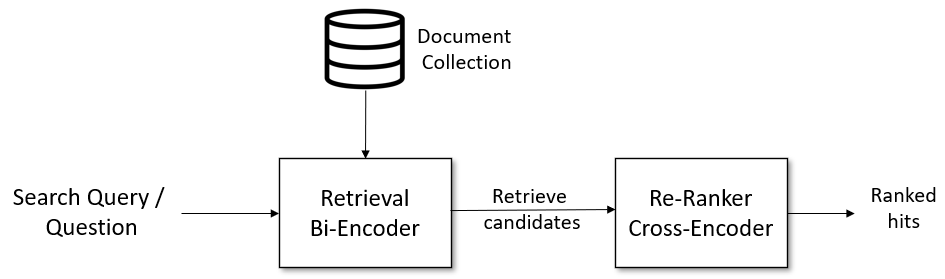
Retireval 엔진으로는 Bi-encoder, Reranker 엔진으로는 Cross-encoder가 많이 쓰인다. Microsoft에서 발표한 Poly-encoder는 Bi-encoder, Cross-encoder의 장점을 취해 Bi-encoder의 성능을 향상시킨 모델이며 효과가 좋은 것으로 알려져있다(원문). 참고로 이 Github에 깔끔하게 구현되어 있다.
1. Introduction
두 입력 sequence에 대한 비교나, 입력 sequence에 대한 label을 얻는 태스크는 다양하다. 대화에서 다음 턴에 적절한 응답이 무엇인지 등에 사용할 수 있다. 이때 encoder를 잘 구성하면 좋은 성능을 낼 수 있는 모델을 만들 수 있는데 자주 쓰이는 encoder는 Bi-encoder, Cross-encoder, Poly-encoder가 있다.
- Bi-encoder: 두개의 입력 sequence에 대해 각각 full self-attention을 수행하고(encoding) aggregate하여 두개의 vector representaion을 얻음(encoder 두개 사용)
- Cross-encoder: 두개의 입력 sequence를 하나의 sequnce로 합쳐 full self-attention을 수행하고(encoding) aggregate하여 하나의 vector representaion을 얻음(encoder 하나 사용)
- Poly-encoder: Bi-encoder처럼 두 개의 encoder를 사용하되 Cross-encoder와 비슷한 full self-attention 효과를 누리기 위한 구조
2. Model
논문에서 Encoder으로는 BERT를 사용하였다. BERT-base 모델을 추가 pre-train하기 위해 Wiki, Toronto Books등의 데이터 문장을 [sent, next sent(or utter)]로 구성하여 MLM, NSP으로 학습하였다고 한다.
Retrieval & Rerank 모델 구조에서 $context \ \& \ candidate \ set$이 존재하는데 $context$는 입력 query, $candidate \ set$은 입력에 대해 적절한 응답을 찾기 위한 search space라고 이해하면 된다. 대부분의 상황에서 $candidate \ set$은 매우 크며($N$) 고정되어 있다.

1) Bi-Encoder
i. Model
두 개의 입력이 있을 때 각각의 sequnce에 대해 독립적으로 encoding하여 두개의 vector representation $Y_{ctxt} = red(T_{1}(ctxt)), Y_{cand} = red(T_{2}(cand))$을 얻는다.
- $T_{1}, T_{2}$: 각기 다른 pre-trained transformer(BERT)
- $T(x)= h_{1}, \cdots, h_{N}$: BERT output(token별 embedding)
- $red(\cdot)$: BERT output에서 하나의 vector를 뽑는 reducer이며, 실험 결과에서 첫번째 token embedding을 사용하는게 성능이 조금 더 좋았다고 한다
ii. Scoring
$y_{ctxt}, \ y_{cand_{i}}$의 dot-product를 사용한다
- $s(ctxt, cand_{i}) = y_{ctxt} \cdot y_{cand_{i}}$
iii. Training
positive set($input, \ label$)으로 학습 셋을 구성(bath size: $n$)하여 학습할 때
- $y_{ctxt} \cdot y_{cand_{i}}, \cdots, y_{ctxt} \cdot y_{cand_{n}}$를 계산하여 $n$개의 logit이 나오며($cand_{i}$: positive label, $n-1$개의 negative label), cross-entroply loss로 학습
- in-batch negative 방식으로 학습이 가능하기 때문에 batch size를 크게 할 수 있음
iv. Inference
$candidate \ set$이 고정이기 때문에 embedding을 미리 계산해둘 수 있다. 즉, 입력 query인 $y_{ctxt}$만 계산하면 되기 때문에 속도가 매우 빠르다.
2) Cross-encoder
i. Model
두 개의 입력 sequence를 하나로 합치고 encoding하여 하나의 vector representaion $y_{ctxt, cand} = first(T(ctxt, cand)) = h_{1}$을 얻을 수 있다.
- candidate, context를 합쳐 self-attention을 계산하기 때문에 rich interactions을 얻을 수 있다고 함(candidate-sensitive input representation)
ii. Scoring
Linear(또는 Non-linear) layer를 통과시켜 score 얻음
- $s(ctxt, cand_{i}) = y_{ctxt,cand_{i}}W$
iii. Training
- n개의 logit $s(ctxt, cand_{i}), \cdots, s(ctxt, cand_{n})$에 대해 cross entropy loss로 학습
- gpu 메모리가 상대적으로 크기 때문에 batch size를 Bi-encoder보다 작게 해야함
- encoding을 매번 새롭게 해야하기 때문에 in-batch negative 방식을 사용할 수 없음
iv. Inference
$candidate \ set$의 임베딩을 매번 새롭게 계산하기 때문에 느리지만 정확도는 높음
3) Poly-encoder(★)

Poly-encoder는 Bi-encoder, Cross-encoder의 장점을 모두 활용하기 위한 모델이다.
- candidate은 Bi-encoder에서 처럼 embedding을 미리 계산해둘 수 있음 → fast inference
- context는 Cross-encoder에서 처럼 candidate과의 joined embedding 계산 → richer information
i. Model
➀ Candidate Encoder: $y_{cand_{i}}$ 계산
➁ Context Feature Encoding:
- $T(x)= h_{1}, \cdots, h_{N}$으로 입력에 대한 embedding 계산
- $m$개의 context code(trainable parameter)를 Query로, input embedding $h_{1}, \cdots, h_{N}$을 Key, Value로 attention 계산하여 $m$개의 context feature 얻음($Emb_{1}, \cdots, Emb_{m}$)
- $Emb_{i} = y^{i}_{ctxt} = \sum_{j}w^{c_{i}}_{j}h_{j} \hspace{0.5cm} where \hspace{0.5cm} (w^{c_{i}}_{1}, \cdots, w^{c_{i}}_{N})=softmax(c_{i}\cdot h_{1}, \cdots, c_{i}\cdot h_{N})$
- $m < N$이기 때문에 Cross-encoder에서의 self-attention보다 속도가 훨씬 빠르며 richer information을 얻을 수 있음
➂ Context Encoding: $y_{ctxt}$ 계산
- $y_{cand_{i}}$을 Query로, context feature $Emb_{1}(y^{i}_{ctxt}), \cdots, Emb_{m}(y^{i}_{ctxt})$를 Key, Value로 attention 계산하여 $y_{ctxt}$ 계산
- $y_{ctxt} = \sum_{i}w_{i}y^{i}_{ctxt} \hspace{0.5cm} where \hspace{0.5cm} (w_{1}, \cdots, w_{m})=softmax(y_{cand_{i}}\cdot y^{1}_{ctxt} \cdots y_{cand_{i}}\cdot y^{m}_{ctxt})$
ii. Scoring
$s(ctxt, cand_{i}) = y_{ctxt} \cdot y_{cand_{i}}$ 또는 Non-linear layer등 사용
3. 실험결과
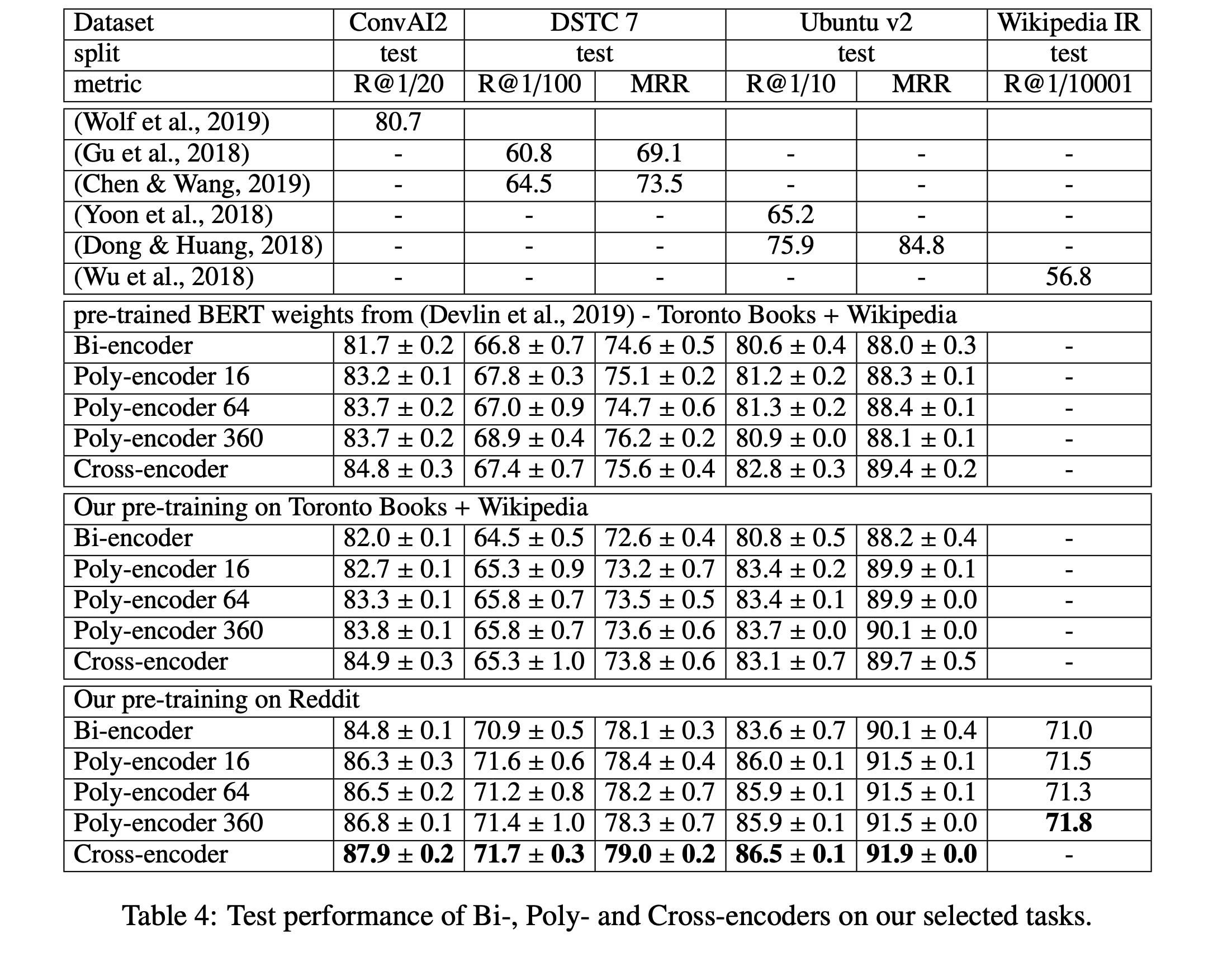
1) Performance
2) Speed

'논문 및 개념 정리' 카테고리의 다른 글
| [2021] LoRA: Low-Rank Adaptation of Large Language Models (0) | 2022.07.14 |
|---|---|
| [2021] GPT Understands, Too (P-tuning) (0) | 2022.04.29 |
| [LM] Perplexity 개념 (0) | 2022.02.17 |
| [GPT3] 주요 내용 정리 (0) | 2022.02.16 |
| [2020] Spot The Bot: A Robust and Efficient Framework for the Evaluation of Conversational Dialogue Systems (0) | 2021.08.13 |
Information retrieval이나 question answering 모델을 구성할 때 매우 큰 search space에서 속도와 성능이 둘다 중요한데 이를 위해 Retrieval & Rerank 구조가 많이 쓰인다(SBERT 설명글).
Retireval 엔진으로는 Bi-encoder, Reranker 엔진으로는 Cross-encoder가 많이 쓰인다. Microsoft에서 발표한 Poly-encoder는 Bi-encoder, Cross-encoder의 장점을 취해 Bi-encoder의 성능을 향상시킨 모델이며 효과가 좋은 것으로 알려져있다(원문). 참고로 이 Github에 깔끔하게 구현되어 있다.
1. Introduction
두 입력 sequence에 대한 비교나, 입력 sequence에 대한 label을 얻는 태스크는 다양하다. 대화에서 다음 턴에 적절한 응답이 무엇인지 등에 사용할 수 있다. 이때 encoder를 잘 구성하면 좋은 성능을 낼 수 있는 모델을 만들 수 있는데 자주 쓰이는 encoder는 Bi-encoder, Cross-encoder, Poly-encoder가 있다.
- Bi-encoder: 두개의 입력 sequence에 대해 각각 full self-attention을 수행하고(encoding) aggregate하여 두개의 vector representaion을 얻음(encoder 두개 사용)
- Cross-encoder: 두개의 입력 sequence를 하나의 sequnce로 합쳐 full self-attention을 수행하고(encoding) aggregate하여 하나의 vector representaion을 얻음(encoder 하나 사용)
- Poly-encoder: Bi-encoder처럼 두 개의 encoder를 사용하되 Cross-encoder와 비슷한 full self-attention 효과를 누리기 위한 구조
2. Model
논문에서 Encoder으로는 BERT를 사용하였다. BERT-base 모델을 추가 pre-train하기 위해 Wiki, Toronto Books등의 데이터 문장을 [sent, next sent(or utter)]로 구성하여 MLM, NSP으로 학습하였다고 한다.
Retrieval & Rerank 모델 구조에서
1) Bi-Encoder
i. Model
두 개의 입력이 있을 때 각각의 sequnce에 대해 독립적으로 encoding하여 두개의 vector representation
ii. Scoring
iii. Training
positive set(
- in-batch negative 방식으로 학습이 가능하기 때문에 batch size를 크게 할 수 있음
iv. Inference
2) Cross-encoder
i. Model
두 개의 입력 sequence를 하나로 합치고 encoding하여 하나의 vector representaion
- candidate, context를 합쳐 self-attention을 계산하기 때문에 rich interactions을 얻을 수 있다고 함(candidate-sensitive input representation)
ii. Scoring
Linear(또는 Non-linear) layer를 통과시켜 score 얻음
iii. Training
- n개의 logit
- gpu 메모리가 상대적으로 크기 때문에 batch size를 Bi-encoder보다 작게 해야함
- encoding을 매번 새롭게 해야하기 때문에 in-batch negative 방식을 사용할 수 없음
iv. Inference
3) Poly-encoder(★)
Poly-encoder는 Bi-encoder, Cross-encoder의 장점을 모두 활용하기 위한 모델이다.
- candidate은 Bi-encoder에서 처럼 embedding을 미리 계산해둘 수 있음 → fast inference
- context는 Cross-encoder에서 처럼 candidate과의 joined embedding 계산 → richer information
i. Model
➀ Candidate Encoder:
➁ Context Feature Encoding:
➂ Context Encoding:
ii. Scoring
3. 실험결과
1) Performance
2) Speed
'논문 및 개념 정리' 카테고리의 다른 글
| [2021] LoRA: Low-Rank Adaptation of Large Language Models (0) | 2022.07.14 |
|---|---|
| [2021] GPT Understands, Too (P-tuning) (0) | 2022.04.29 |
| [LM] Perplexity 개념 (0) | 2022.02.17 |
| [GPT3] 주요 내용 정리 (0) | 2022.02.16 |
| [2020] Spot The Bot: A Robust and Efficient Framework for the Evaluation of Conversational Dialogue Systems (0) | 2021.08.13 |