
이미지, 텍스트(title or description) 쌍을 활용하여 효과적인 이미지 representaion을 학습한 방법인 CLIP(Contrastive Language-Image Pre-training) 논문을 정리하고자 한다.(논문링크, openAI 블로그 글)
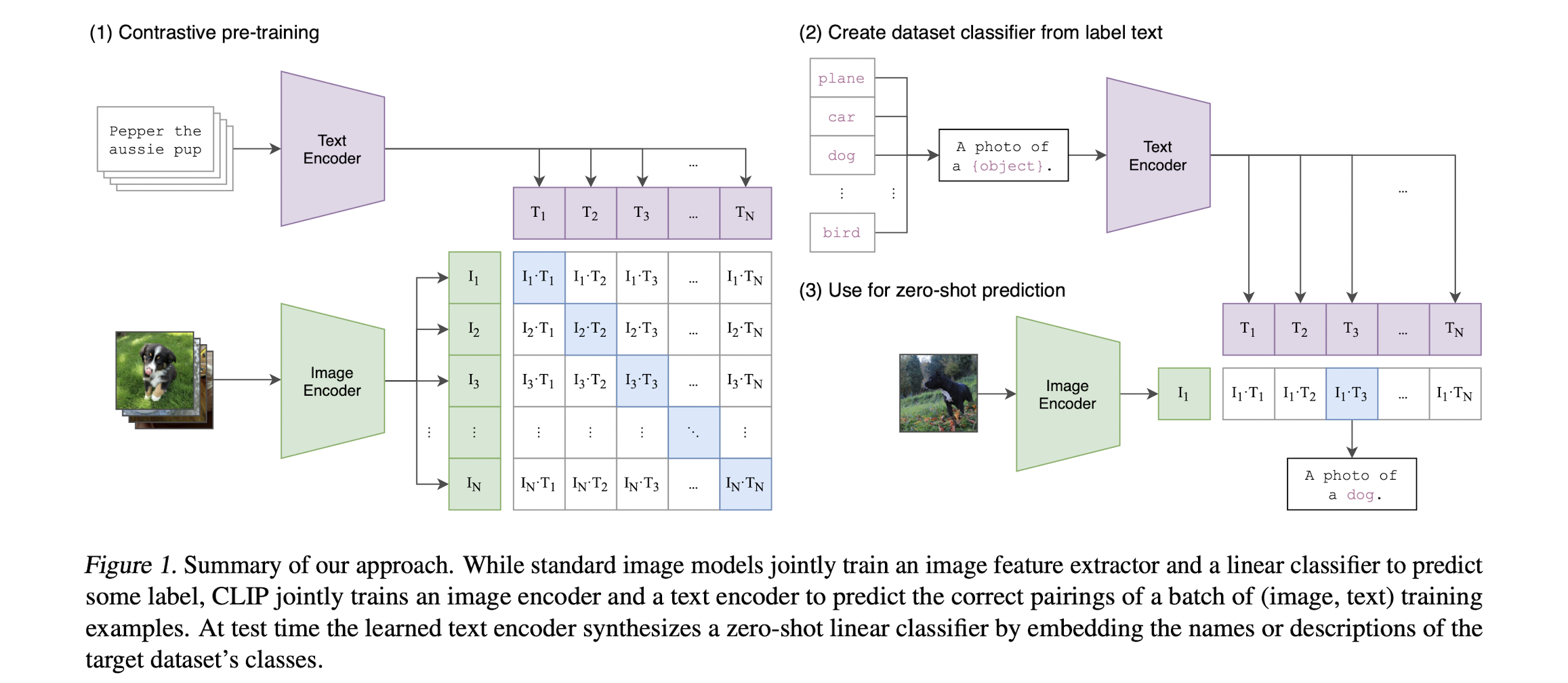
1. Introduction
최근의 딥러닝 모델들은 auto-regressive, MLM과 같이 task-agnostic objective를 사용하되 모델사이즈를 키워 성능을 매우 올려왔으며, 기존의 crowd-labeled 데이터셋 보다 웹상에서 모은 데이터셋을 활용하는게 더 효과적이었다. Computer vision의 경우 여전히 label set이 고정된 형태의 데이터가 많이 사용되고 있었으며 때문에 확장성이 있는 모델을 만드는데 한계가 있었다. 자연어 표현을 label로 활용한 연구들도 있었지만 zero-shot 성능이 매우 떨어지는 한계도 있었다.
본 연구에서는 ➀ natural languague supervision, ➁ scale(모델 크기), ➂large web data를 적용한 pre-trained image classifier의 성능을 연구했으며 그 결과 GPT 계열과 마찬가지로 OCR, geo-localization 등과 같은 다양한 태스크에서 좋은 성능을 보이는 것을 확인하였다.
2. Approach
1) Natural Language Supervision
핵심 아이디어는 자연어에 담겨있는 인간의 인지, 지각(perception)을 학습하는 것이다(learning perception from supervision contained in natural language). 대부분의 연구들은 이를 unsupervised, self-supervised, 혹은 supervised와 같이 표현하는데 CLIP 논문에서는 자연어 label 존재 여부와 관계 없이 자연어 자체를 사용하는 방법을 사용하였다(supversion). 이러한 방법은 매우 많은 데이터로 scale을 키울 수 있고, 자연어의 개념이 담긴 representation을 학습하여 zero-shot 성능을 향상시킬 수 있다.
2) Creating a Sufficiently Large Dataset
기존의 computer vision 데이터셋들은 많은 비용을 들여 crowd sourcing으로 데이터에 label을 달았다. CLIP에서는 웹에서 (image, text) 데이터를 모으되 무의미한 text를 거르기 위해 등장 빈도가 비교적 높은 단어들로 필터링하여 데이터셋을 구축하였다.
3) Selecting an Efficient Pre-Training Method
CLIP에서는 image-text pre-training을 위해 효과적인 학습 방법을 찾는 것이 매우 중요하였다고 한다. 첫번째로 시도한 방법은 CNN & text transformer + autoregressive caption text 학습방법이었는데 비효율적이었다고 한다. 이미지마다 정확한 token을 학습하는 것은 학습 효율성 뿐만 아니라 이미지의 표현 다양성을 해치기도 한다.
최근 연구들에서는 contrastive representation learning이 효과적인 방법임이 증명되고 있고 이미지의 generative model을 학습시키는 방법보다 계산량이 적다. CLIP에서는 이에 착안하여 text 자체를 학습하는게 아닌 이미지가 어떤 whole text와 쌍인지를 학습하는 방법을 사용하였다. [그림1]에서 처럼 $N$개의 (image, text) 쌍이 있을 때 $N$개의 정답에 대한 cosine similarity는 극대화하고 $N^{2}-N$개의 쌍의 cosine similarity는 낮추는 방법으로 학습하였다.
4) Choosing and Scaling a Model
CLIP에서는 image encoder로 몇 가지 변형이 추가된 ResNet-50, ViT(Vision Transformer) 두개를 사용하였고 text encoder로는 Transformer를 활용하였다.
3. Experiments
1) Zero-Shot Transfer
비전 분야에서 zero-shot learning은 일반적으로 처음보는 카테고리(클래스)에 대한 분류를 의미한다. 논문에서는 CLIP 모델은 pre-train 방법이기 때문에 GPT처럼 zero-shot transfer를 task-learning 관점에서 성능을 분석했으며, 각 데이터셋에서 클래스는 한정되어 있기 때문에 아래와 같이 클래스에 대한 확률을 계산하였다.
For each dataset, we use the names of all the classes in the dataset as the set of potential text pairings and predict the most probable (image, text) pair according to CLIP. In a bit more detail, we first compute the feature embedding of the image and the feature embedding of the set of possible texts by their respective encoders. The cosine similarity of these embeddings is then calculated, scaled by a temperature parameter τ , and normalized into a probability distribution via a softmax
CLIP에서도 prompt engineering이 필요했는데, "A photo of a {label}"과 같은 형태로 label을 예측했으며, 데이터셋에 따라 "A photo of a {label}, a type of pet", "a satellite photo of a {label}"과 같은 부가적인 설명을 추가하였다.
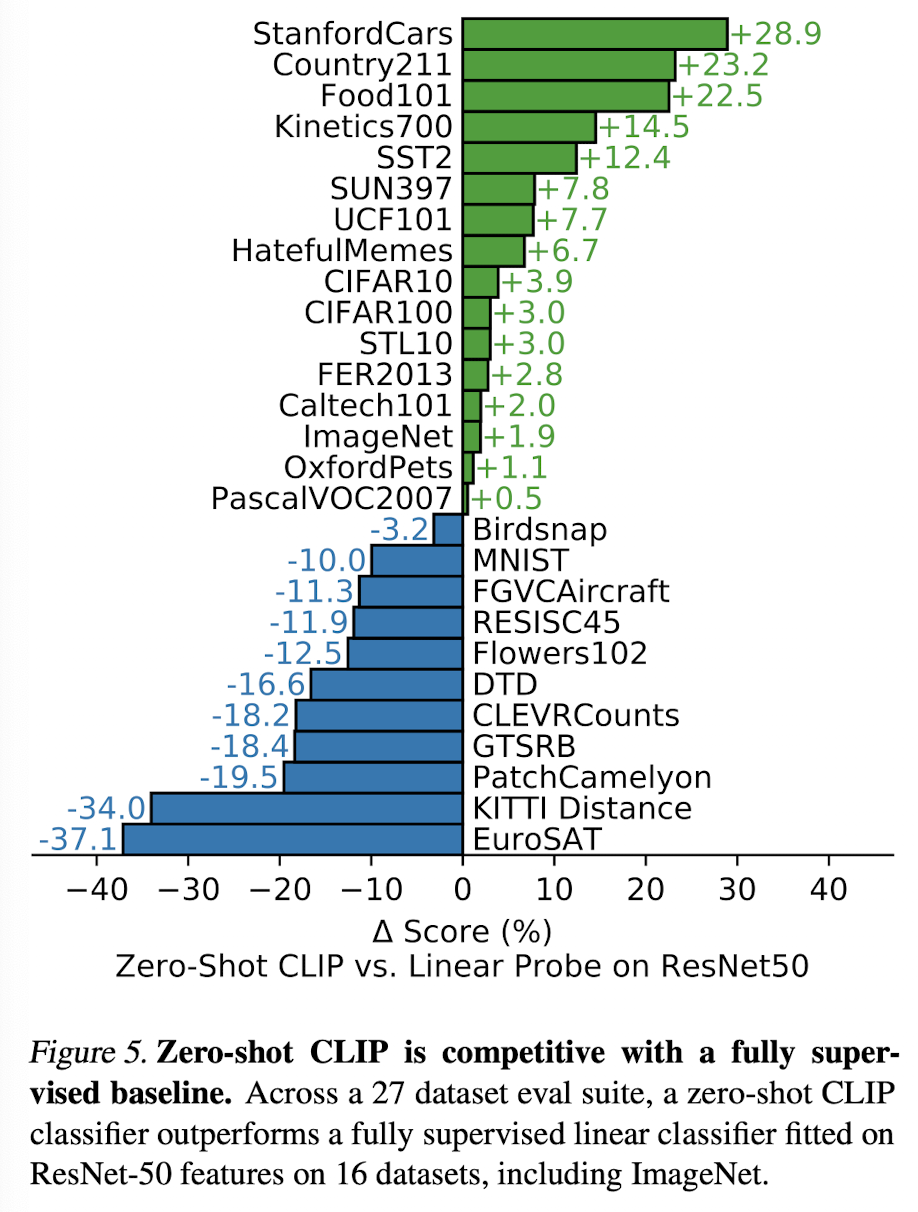
CLIP의 zero-shot 성능은 어떨까? 위 그림은 fully supervised된 ResNet-50 모델과의 데이터셋별 성능 비교이다. CLIP은 specialized, complex, abstract 태스크에서 성능이 낮으며 단순한 이미지 분류에서는 좋은 성능을 보인다.
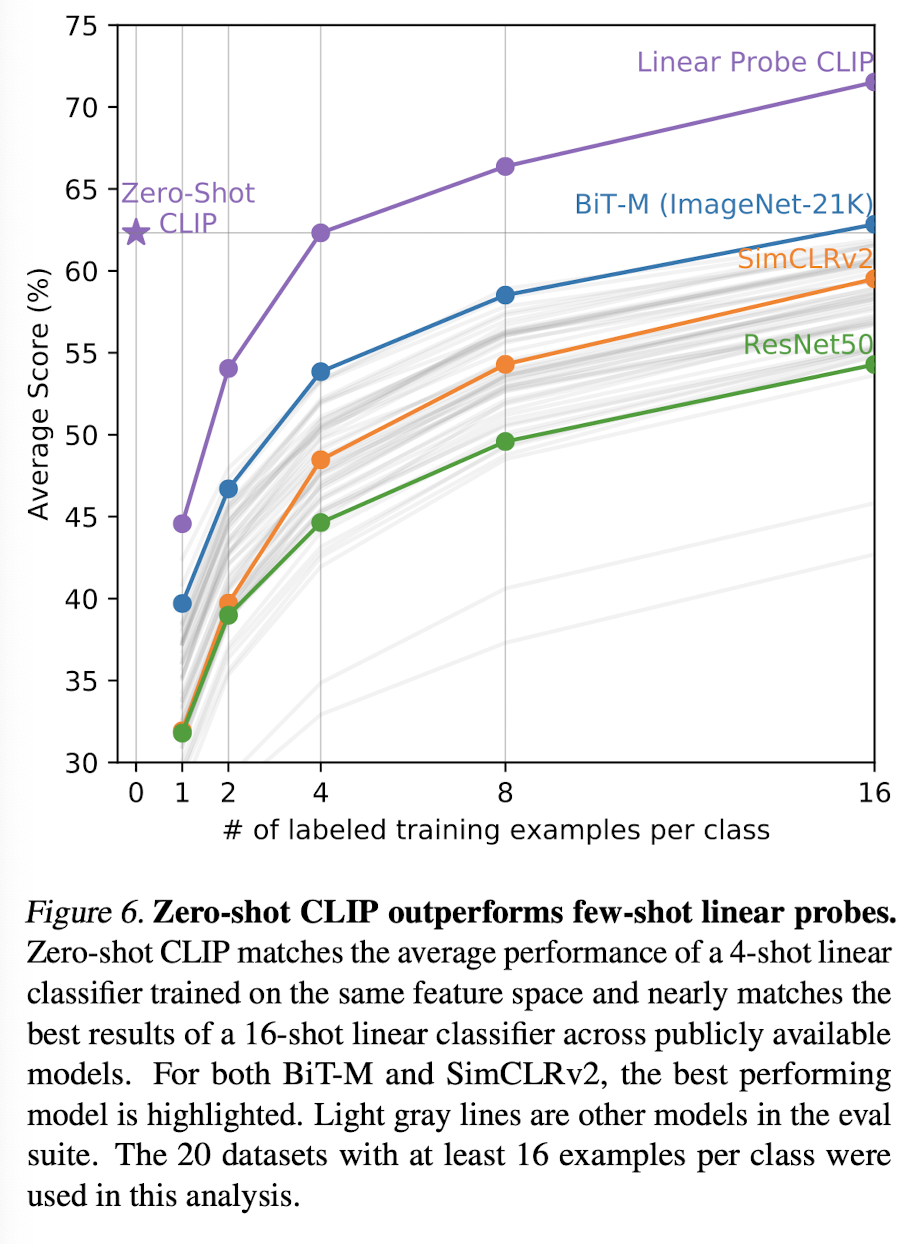
CLIP zero-shot과 few-shot logistic regression과의 성능비교는 어떨까? CLIP 모델의 zero-shot 성능은 같은 embedding으로 4개의 이미지를 학습했을 때의 성능과 비슷하다. 그 이유를 논문에서는 아래와 같이 설명하고 있다.
This is likely due to an important difference between the zero-shot and few-shot approach. First, CLIP’s zero-shot classifier is generated via natural language which allows for visual concepts to be directly specified (“communicated”). By contrast, “normal” supervised learning must infer concepts indirectly from training examples. Context-less example-based learning has the drawback that many different hypotheses can be consistent with the data, especially in the one-shot case
2) Representation Learning
CLIP의 task-learning 성능도 중요하지만 representation learning도 살펴볼 필요가 있다. 일반적으로는 representation을 입력으로 linear classifier를 학습거나(linear probing), 데이터셋별로 end-to-end로 fine-tune하여 representation learning 성능을 측정하는데 CLIP에서는 linear classifier를 사용하였다.
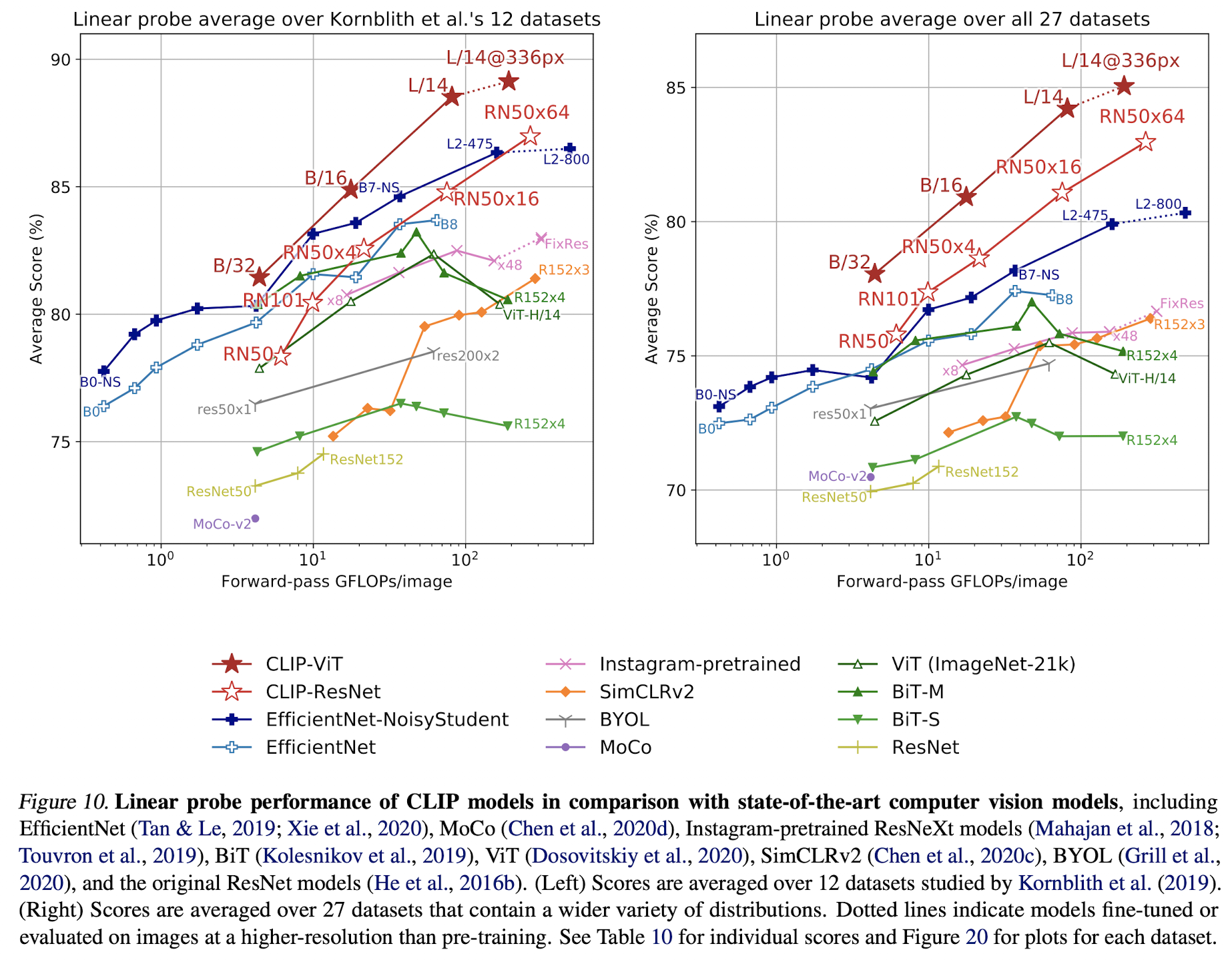
결론적으로 CLIP 모델은 성능, 계산 효율성 측면에서 모두 매우 좋은 성능을 보여준다. 저자들은 CLIP이 pre-train 과정에서 end-to-end fine-tuning 보다 더 많은 task들의 정보를 학습했기 때문이라고 분석하였다.
3) Robustness to Natural Distribution Shift
딥러닝이 핫해지던 시절에 ImageNet과 같은 데이터셋에서 사람을 뛰어넘었다는 말이 뉴스에 나오곤 했었다. 하지만 실제로는 학습한 데이터셋에서의 in-distribution 성능만 좋다는 결론이 났다고 한다. 저자들은 CLIP이 매우 많은 이미지 데이터를 natural language supervision과 함께 학습했고 zero-shot 성능도 좋기 때문에 generalization 성능도 분석하고자 하였다. ImageNet은 여러가지 변형 데이터가 존재하는데 이들에 대한 성능을 측정하면 natural distribution shift에 강하거나 약한지 분석해볼 수 있다.
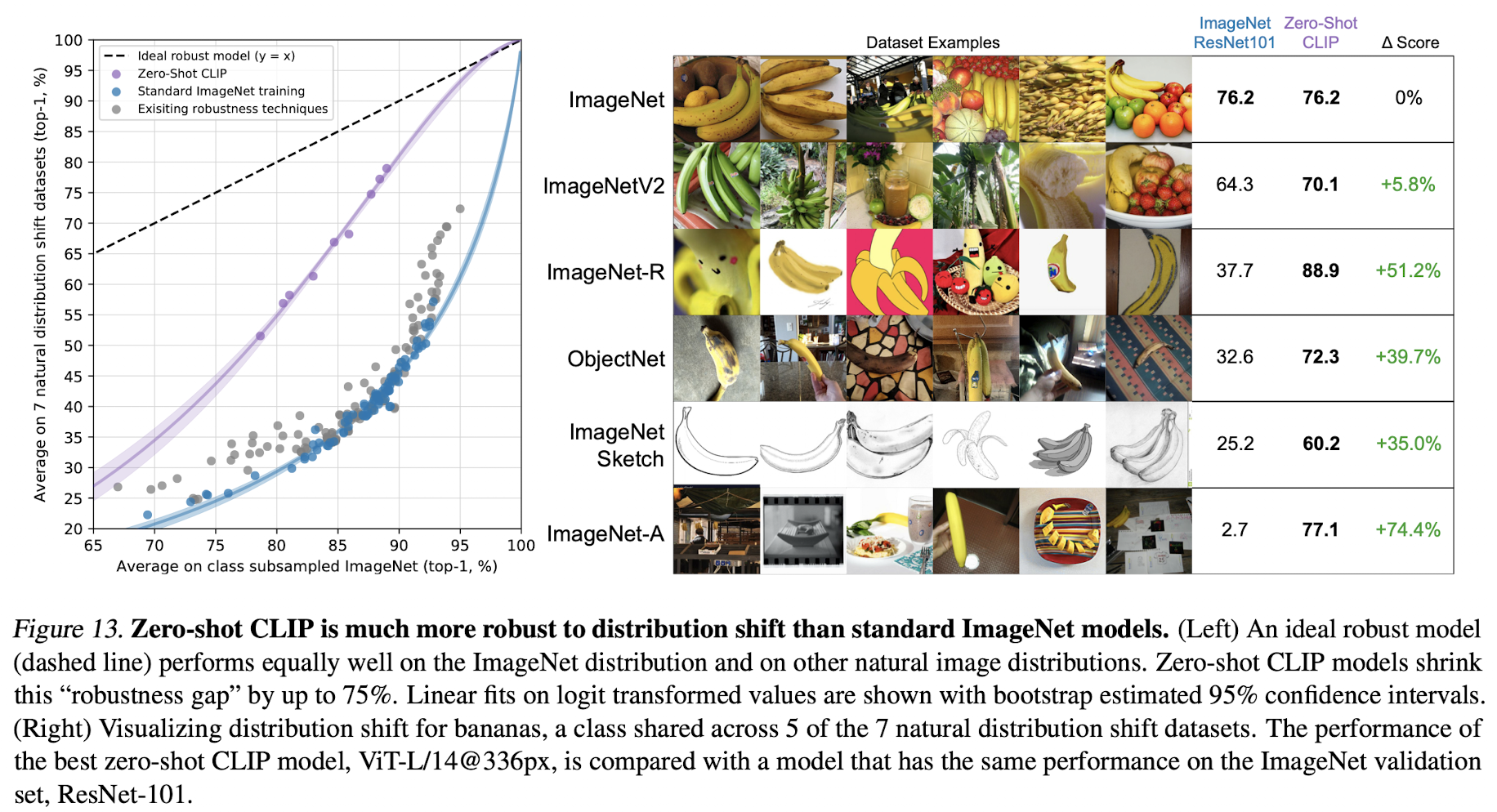
위 그림에서 확인할 수 있듯 CLIP zero-shot은 distribution shift에 robust하다.
'논문 및 개념 정리' 카테고리의 다른 글
이미지, 텍스트(title or description) 쌍을 활용하여 효과적인 이미지 representaion을 학습한 방법인 CLIP(Contrastive Language-Image Pre-training) 논문을 정리하고자 한다.(논문링크, openAI 블로그 글)
1. Introduction
최근의 딥러닝 모델들은 auto-regressive, MLM과 같이 task-agnostic objective를 사용하되 모델사이즈를 키워 성능을 매우 올려왔으며, 기존의 crowd-labeled 데이터셋 보다 웹상에서 모은 데이터셋을 활용하는게 더 효과적이었다. Computer vision의 경우 여전히 label set이 고정된 형태의 데이터가 많이 사용되고 있었으며 때문에 확장성이 있는 모델을 만드는데 한계가 있었다. 자연어 표현을 label로 활용한 연구들도 있었지만 zero-shot 성능이 매우 떨어지는 한계도 있었다.
본 연구에서는 ➀ natural languague supervision, ➁ scale(모델 크기), ➂large web data를 적용한 pre-trained image classifier의 성능을 연구했으며 그 결과 GPT 계열과 마찬가지로 OCR, geo-localization 등과 같은 다양한 태스크에서 좋은 성능을 보이는 것을 확인하였다.
2. Approach
1) Natural Language Supervision
핵심 아이디어는 자연어에 담겨있는 인간의 인지, 지각(perception)을 학습하는 것이다(learning perception from supervision contained in natural language). 대부분의 연구들은 이를 unsupervised, self-supervised, 혹은 supervised와 같이 표현하는데 CLIP 논문에서는 자연어 label 존재 여부와 관계 없이 자연어 자체를 사용하는 방법을 사용하였다(supversion). 이러한 방법은 매우 많은 데이터로 scale을 키울 수 있고, 자연어의 개념이 담긴 representation을 학습하여 zero-shot 성능을 향상시킬 수 있다.
2) Creating a Sufficiently Large Dataset
기존의 computer vision 데이터셋들은 많은 비용을 들여 crowd sourcing으로 데이터에 label을 달았다. CLIP에서는 웹에서 (image, text) 데이터를 모으되 무의미한 text를 거르기 위해 등장 빈도가 비교적 높은 단어들로 필터링하여 데이터셋을 구축하였다.
3) Selecting an Efficient Pre-Training Method
CLIP에서는 image-text pre-training을 위해 효과적인 학습 방법을 찾는 것이 매우 중요하였다고 한다. 첫번째로 시도한 방법은 CNN & text transformer + autoregressive caption text 학습방법이었는데 비효율적이었다고 한다. 이미지마다 정확한 token을 학습하는 것은 학습 효율성 뿐만 아니라 이미지의 표현 다양성을 해치기도 한다.
최근 연구들에서는 contrastive representation learning이 효과적인 방법임이 증명되고 있고 이미지의 generative model을 학습시키는 방법보다 계산량이 적다. CLIP에서는 이에 착안하여 text 자체를 학습하는게 아닌 이미지가 어떤 whole text와 쌍인지를 학습하는 방법을 사용하였다. [그림1]에서 처럼
4) Choosing and Scaling a Model
CLIP에서는 image encoder로 몇 가지 변형이 추가된 ResNet-50, ViT(Vision Transformer) 두개를 사용하였고 text encoder로는 Transformer를 활용하였다.
3. Experiments
1) Zero-Shot Transfer
비전 분야에서 zero-shot learning은 일반적으로 처음보는 카테고리(클래스)에 대한 분류를 의미한다. 논문에서는 CLIP 모델은 pre-train 방법이기 때문에 GPT처럼 zero-shot transfer를 task-learning 관점에서 성능을 분석했으며, 각 데이터셋에서 클래스는 한정되어 있기 때문에 아래와 같이 클래스에 대한 확률을 계산하였다.
For each dataset, we use the names of all the classes in the dataset as the set of potential text pairings and predict the most probable (image, text) pair according to CLIP. In a bit more detail, we first compute the feature embedding of the image and the feature embedding of the set of possible texts by their respective encoders. The cosine similarity of these embeddings is then calculated, scaled by a temperature parameter τ , and normalized into a probability distribution via a softmax
CLIP에서도 prompt engineering이 필요했는데, "A photo of a {label}"과 같은 형태로 label을 예측했으며, 데이터셋에 따라 "A photo of a {label}, a type of pet", "a satellite photo of a {label}"과 같은 부가적인 설명을 추가하였다.
CLIP의 zero-shot 성능은 어떨까? 위 그림은 fully supervised된 ResNet-50 모델과의 데이터셋별 성능 비교이다. CLIP은 specialized, complex, abstract 태스크에서 성능이 낮으며 단순한 이미지 분류에서는 좋은 성능을 보인다.
CLIP zero-shot과 few-shot logistic regression과의 성능비교는 어떨까? CLIP 모델의 zero-shot 성능은 같은 embedding으로 4개의 이미지를 학습했을 때의 성능과 비슷하다. 그 이유를 논문에서는 아래와 같이 설명하고 있다.
This is likely due to an important difference between the zero-shot and few-shot approach. First, CLIP’s zero-shot classifier is generated via natural language which allows for visual concepts to be directly specified (“communicated”). By contrast, “normal” supervised learning must infer concepts indirectly from training examples. Context-less example-based learning has the drawback that many different hypotheses can be consistent with the data, especially in the one-shot case
2) Representation Learning
CLIP의 task-learning 성능도 중요하지만 representation learning도 살펴볼 필요가 있다. 일반적으로는 representation을 입력으로 linear classifier를 학습거나(linear probing), 데이터셋별로 end-to-end로 fine-tune하여 representation learning 성능을 측정하는데 CLIP에서는 linear classifier를 사용하였다.
결론적으로 CLIP 모델은 성능, 계산 효율성 측면에서 모두 매우 좋은 성능을 보여준다. 저자들은 CLIP이 pre-train 과정에서 end-to-end fine-tuning 보다 더 많은 task들의 정보를 학습했기 때문이라고 분석하였다.
3) Robustness to Natural Distribution Shift
딥러닝이 핫해지던 시절에 ImageNet과 같은 데이터셋에서 사람을 뛰어넘었다는 말이 뉴스에 나오곤 했었다. 하지만 실제로는 학습한 데이터셋에서의 in-distribution 성능만 좋다는 결론이 났다고 한다. 저자들은 CLIP이 매우 많은 이미지 데이터를 natural language supervision과 함께 학습했고 zero-shot 성능도 좋기 때문에 generalization 성능도 분석하고자 하였다. ImageNet은 여러가지 변형 데이터가 존재하는데 이들에 대한 성능을 측정하면 natural distribution shift에 강하거나 약한지 분석해볼 수 있다.
위 그림에서 확인할 수 있듯 CLIP zero-shot은 distribution shift에 robust하다.