
언어모델로 generation 시 특정 입력에 더 집중된 문장이 생성될 수 있도록 한 모델에 대해 정리하고자 한다(논문링크).

1. Introduction
현재 대부분의 언어모델은 transformer의 attention 메커니즘을 기반으로 하며 corpus만 주어지면 언어적인 특성과 주어진 입력을 잘 반영한 contextualized embedding을 생성할 수 있다. 하지만 입력 컨텍스트의 특정 부분에 집중하고 싶어도 기존의 attention 메커니즘 만으로는 이를 구현하기가 어렵다.
본 연구는 focus vector를 학습하여 이를 해결하고자 하였으며 주요 포인트는 다음과 같다.
- trainable focus vector의 효과를 탐색함. 이때 기존의 언어모델의 파라미터는 고정시켜 활용할 수 있다.
- Attribution method를 활용하여 automatic highlighting이 가능하며 추가 annotation이 없어도 된다.
- focus vector가 학습이 완료되면 사용자가 입력의 특정 span을 highlighting하면, 모델이 해당 span에 더 집중된 문장을 생성할 수 있다.
2. Model
0) Denotation
- $x = \{x_{1}, \cdots, x_{1}\}$: input token sequence / $y$: target token sequence
- $c_{i}$: $i^{th}$번째 token이 highlight 되어있는지 표기하기 위한 binary indicator
- $d$: transformer의 embedding dimension
- $h_{i}^{l}$: transformer Encoder에서 $i^{th}$번째 token의 $l$ 번째 layer에서의 embedding, $h_{i}^{0}$: 입력 embedding
- atttention weight: 각 Decoder layer에서 Encoder output과 multi-head cross-attention을 수행한다. 이때 $l^{th}$ Decoder layer에서 $h^{th}$ head에서의 attention weight을 다음과 같이 정의한다.
$$\alpha_{i,j}^{h,l} = \underset{i \in \{1,,,n\}}{\text{softmax}}(\frac{k(h_{i}^{L})\cdot q_{j}^{h,l}}{\sqrt{d}})$$
$k(\cdot)$은 linear transformation을 의미하고, $\alpha_{i,j}$는 query vector $q_{j}$의 $j^{th}$번째와 encoder output $h_{i}^{L}$와의 attention weight을 의미한다.
- $P_{M}(y|x)$: input $x$에 대해 $y$에 대해 부여된 확률(language model)
1) Attribution Methods
본 연구에서 제안된 방법은 1) Attribution method를 활용해서 automatic highlight annotation을 얻고 2) annotation을 활용해서 focus vector를 학습하는 방향을 진행된다.
Attribution method는 saliency maps 등으로 불리는데, 모델의 각 입력 feature가 모델의 결과에 얼마나 영향을 미치는지를 분석하는 방법이다. 자세한 내용은 GCP글, Medium글을 참고하면 좋다.
본 논문에서는 자주 쓰이는 아래의 4가지 방법을 실험했으며 각 방법은 각기 다른 방식으로 attribution score(모델 $P_{M}$, input $x$, target $y$이 있을 때 주어진 문장 $S$에 대한 score)를 계산한다.
*Leave-out-out(LOO)
문장 $S$의 token을 $<\text{pad}>$로 치환하여 $\text{NLL loss}$의 차이를 계산한 값이며 occlusion-based method라고도 불린다. 실험 결과 LOO 방식이 사람의 label 방식과 제일 유사했다.
$$A(S) = \text{log}P_{M}(y|x)-\text{log}P_{M}(y|x_{S-padded})$$
*Attention-weight
문장 $S$의 모든 token들에 대해서 모든 Decoder layer에서 모든 attention head에서의 attention weight의 합이다.
$$A(S) = \sum_{i \in S}\sum_{j,h,l}\alpha_{i,j}^{h,l}$$
*Grad-norm
문장 $S$의 input word embedding들의 norm of gradient의 합이다.
$$A(S) = \sum_{i \in S}\left\| \nabla_{h_{i}^{0}} \text{log} P_{M}(y|x) \right\|_{2}$$
*Grad-input-product
모든 입력 token에 대해서 input embedding과 gradient of input embedding의 dot-product 합이다.
$$A(S) = \sum_{i \in S}(\nabla_{h_{i}^{0}} \text{log} P_{M}(y|x)) \cdot h_{i}^{0}$$
LOO를 활용한 automatic annotation은 다음과 같다. 문장의 token들을 LOO attribution score 기준으로 내림차순으로 정렬하고, 태스크에 따라 앞에 $n$개 token을 highlight으로 지정한다. 이후 각 token들에 대한 binary indicator varaible $c^{attr} = \{c_{1}^{attr}, \cdots, c_{n}^{attr} \}$를 얻고 focus vector 학습에 사용한다.
2) Focus Vectors
모델이 특정 입력에 집중되도록 컨트롤하기 위해 focus vector를 학습해서 사용할 수 있다. Focus vector는 $d$ 차원 vector $\theta$이며 모델의 input embedding에 추가로 더해지는 embedding vector이다.
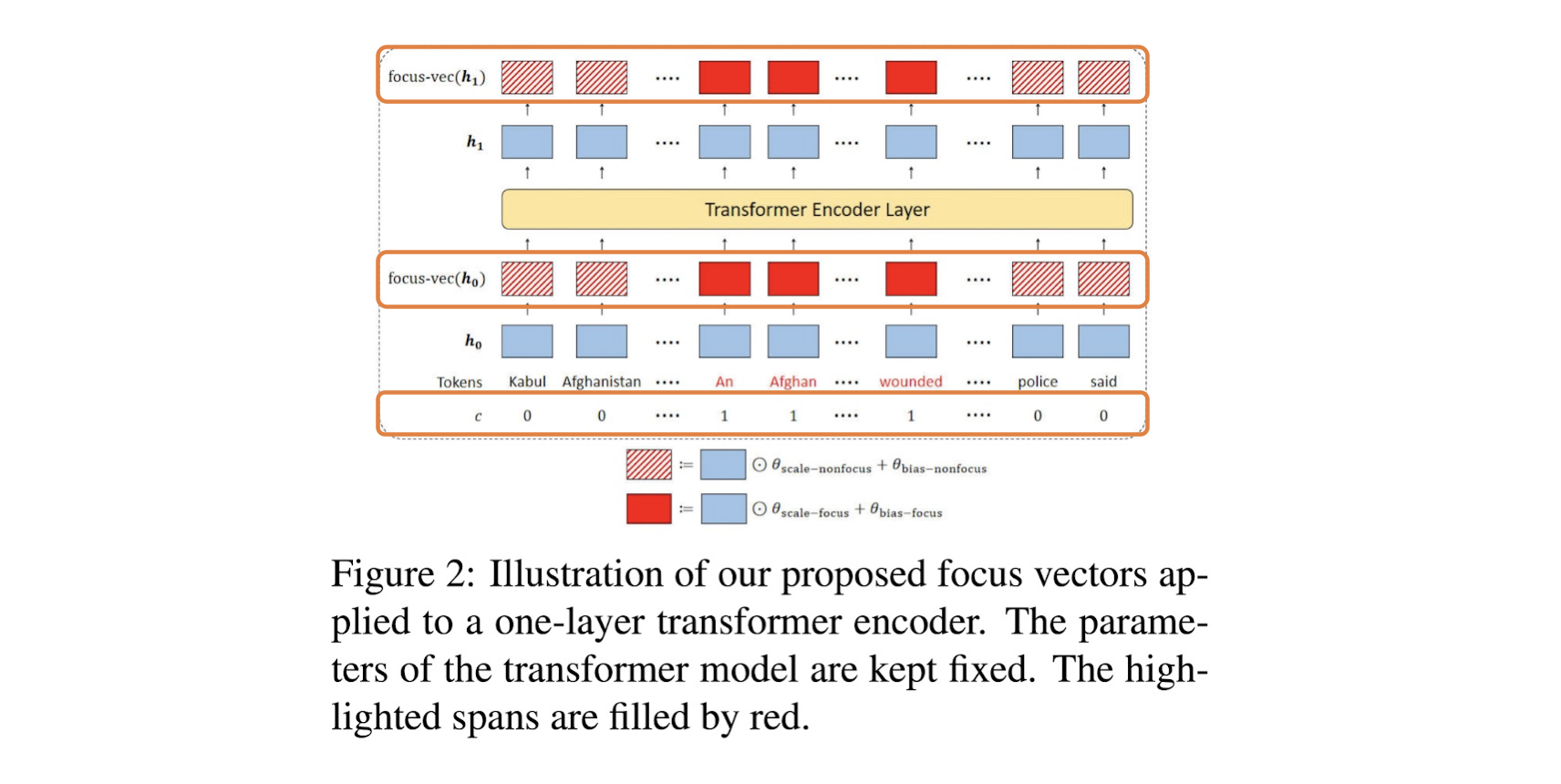
$$f(h_{i}^{l}) = \left\{ \begin{array}{cl}
& h_{i}^{l} \odot \theta_{\text{scale-focus}}^l{} + \theta_{\text{bias-focus}}^l{}, & \text{if} \ \ c_{i}^{attr}=1 \\
& h_{i}^{l} \odot \theta_{\text{scale-nonfocus}}^l{} + \theta_{\text{bias-nonfocus}}^l{}, & \text{if} \ \ c_{i}^{attr}=0
\end{array} \right.$$
$\odot$은 Hadamard product(element-wise product)를 의미한다. 이후 원래의 언어모델이 학습되듯 NLL loss와 SGD로 학습한다.
$$L(x,y,c^{attr};\theta) = -\text{log}P_{focus}(y|x,c^{attr})$$
3. Result
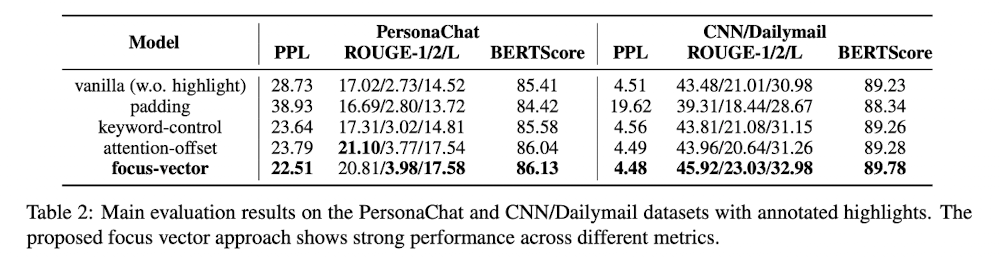
먼저 자체적으로 구비한 데이터셋 기준으로는 ppl, BERTScore 모두 좋다. 또한 이 글의 첫 번째 그림에서도 볼 수 있듯 같은 문장에서 'I have a dog named pedro' 또는 'I work in the healthcare industry' 중 어디에 focus vector가 적용되냐에 따라서 문장 생성 결과가 달라지는 것을 확인할 수 있다.
'논문 및 개념 정리' 카테고리의 다른 글
언어모델로 generation 시 특정 입력에 더 집중된 문장이 생성될 수 있도록 한 모델에 대해 정리하고자 한다(논문링크).
1. Introduction
현재 대부분의 언어모델은 transformer의 attention 메커니즘을 기반으로 하며 corpus만 주어지면 언어적인 특성과 주어진 입력을 잘 반영한 contextualized embedding을 생성할 수 있다. 하지만 입력 컨텍스트의 특정 부분에 집중하고 싶어도 기존의 attention 메커니즘 만으로는 이를 구현하기가 어렵다.
본 연구는 focus vector를 학습하여 이를 해결하고자 하였으며 주요 포인트는 다음과 같다.
- trainable focus vector의 효과를 탐색함. 이때 기존의 언어모델의 파라미터는 고정시켜 활용할 수 있다.
- Attribution method를 활용하여 automatic highlighting이 가능하며 추가 annotation이 없어도 된다.
- focus vector가 학습이 완료되면 사용자가 입력의 특정 span을 highlighting하면, 모델이 해당 span에 더 집중된 문장을 생성할 수 있다.
2. Model
0) Denotation
- atttention weight: 각 Decoder layer에서 Encoder output과 multi-head cross-attention을 수행한다. 이때
1) Attribution Methods
본 연구에서 제안된 방법은 1) Attribution method를 활용해서 automatic highlight annotation을 얻고 2) annotation을 활용해서 focus vector를 학습하는 방향을 진행된다.
Attribution method는 saliency maps 등으로 불리는데, 모델의 각 입력 feature가 모델의 결과에 얼마나 영향을 미치는지를 분석하는 방법이다. 자세한 내용은 GCP글, Medium글을 참고하면 좋다.
본 논문에서는 자주 쓰이는 아래의 4가지 방법을 실험했으며 각 방법은 각기 다른 방식으로 attribution score(모델
*Leave-out-out(LOO)
문장
*Attention-weight
문장
*Grad-norm
문장
*Grad-input-product
모든 입력 token에 대해서 input embedding과 gradient of input embedding의 dot-product 합이다.
LOO를 활용한 automatic annotation은 다음과 같다. 문장의 token들을 LOO attribution score 기준으로 내림차순으로 정렬하고, 태스크에 따라 앞에
2) Focus Vectors
모델이 특정 입력에 집중되도록 컨트롤하기 위해 focus vector를 학습해서 사용할 수 있다. Focus vector는
3. Result
먼저 자체적으로 구비한 데이터셋 기준으로는 ppl, BERTScore 모두 좋다. 또한 이 글의 첫 번째 그림에서도 볼 수 있듯 같은 문장에서 'I have a dog named pedro' 또는 'I work in the healthcare industry' 중 어디에 focus vector가 적용되냐에 따라서 문장 생성 결과가 달라지는 것을 확인할 수 있다.